nio

转载自 海纳老师的专栏 https://zhuanlan.zhihu.com/p/27296046 但结合网上内容做了比较大的改动
感谢海纳老师,我的Java进阶路上的引路人,三年前初到北京找工作的时候就看的海纳老师的专栏,三年后再看还是会有收获。
本文也参考 https://www.cnblogs.com/yulinfeng/p/8095326.html https://www.jianshu.com/p/2b71ea919d49 https://juejin.cn/post/6844903440573792270
关于Java io的部分我们就略过了,只需记住io主要是针对文件写入输出操作的, 分为字节流和字符流,是基于流操作的。
而nio是为了解决网络编程问题诞生的。
接下来对于非阻塞式输入输出(NIO)的学习以及理解首先从它的三个基础概念讲起。
基础概念
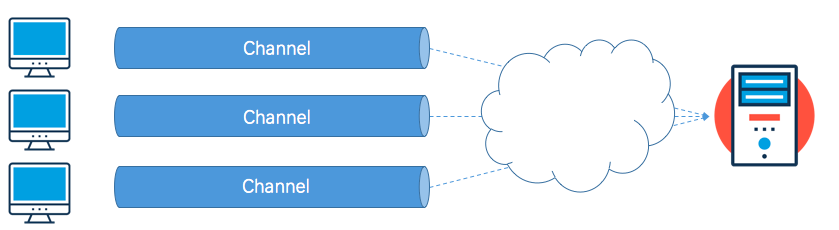
Channel(通道)
在NIO中,你需要忘掉“流”这个概念,取而代之的是“通道”。举例在网络应用程序中有多个客户端连接,此时数据传输的概念并不是“流”而“通道”,通道与流最大的不同就是,通道是双向的,而流是单向的(例如InputStream、OutputStream)。
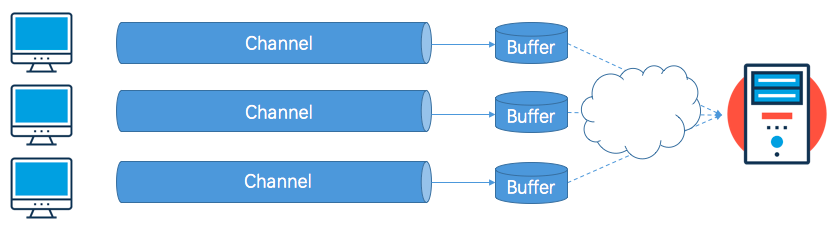
Buffer(缓冲区)
在NIO中并不是简单的将流的概念替换为了通道,与通道搭配的是缓冲区。在BIO的字节流中并不会使用到缓冲区,而是直接操作文件通过字节方式直接读取,而NIO则不同,它会将通道中的数据读入缓存区,或者将缓存区的数据写入通道。
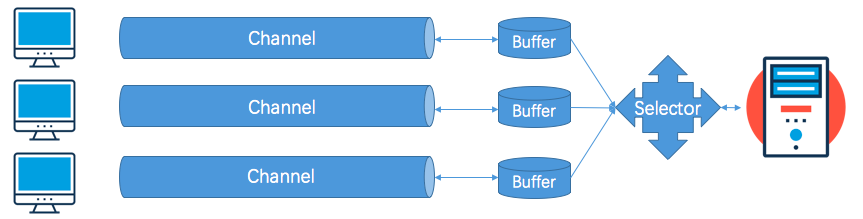
Selector(选择器)
如果使用NIO的应用程序中只有一个Channel,选择器则是可以不需要的,而如果有多个Channel,换言之有多个连接时,此时通过选择器,在服务器端的应用程序中就只需要1个线程对多个连接进行管理。当然从最开始就说到Channel是双向的,所以在最终图的示例为下图所示:
接下来进行详细的介绍
buffer
在没有使用nio之前,我们只能自己维护一个byte数组或者是char数组来进行批量读写,或者使用BufferedReader,BufferedInputStream来做读写缓冲。在nio里,就可以使用buffer了。
缓冲区基础
本质上,缓冲区是就是一个数组。所有的缓冲区都具有四个属性来提供关于其所包含的数组的信息。它们是:
- 容量(Capacity) 缓冲区能够容纳的数据元素的最大数量。容量在缓冲区创建时被设定,并且永远不能被改变。
- 上界(Limit) 缓冲区里的数据的总数,代表了当前缓冲区中一共有多少数据。
- 位置(Position) 下一个要被读或写的元素的位置。Position会自动由相应的 get( )和 put( )函数更新。
- 标记(Mark) 一个备忘位置。用于记录上一次读写的位置。一会儿,我会通过reset方法来说明这个属性的含义。
我们以字节缓冲区为例,ByteBuffer是一个抽象类,不能直接通过 new 语句来创建,只能通过一个static方法 allocate 来创建:
// allocate是堆内内存,allocateDirect是对外内存
ByteBuffer byteBuffer = ByteBuffer.allocate(256);
以上的语句可以创建一个大小为256字节的ByteBuffer,此时,mark = -1, pos = 0, limit = 256, capacity = 256。capacity在初始化的时候确定了,运行时就不会再变化了,而另外三个变量是随着程序的执行而不断变化的。
缓冲区的存取
缓冲区用于存取的方法定义主要是put , get。
put 方法有多种重载,我们看其中一个:
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
final int nextPutIndex() { // package-private
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
这个方法是把一个byte变量 x 放到缓冲区中去。position会加1。再来看一下get方法,也是从position的位置去取缓冲区中的一个字节:
public byte get() {
return hb[ix(nextGetIndex())];
}
final int nextGetIndex() { // package-private
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
那比如,我要是想在一个Buffer中放入了数据,然后想从中读取的话,就要把position调到我想读的那个位置才行。为此,ByteBuffer上定义了一个方法:
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
这里面用到了limit,想一下上面的定义,limit代表可写或者可读的总数。一个新创建的bytebuffer,它可写的总数就是它的capacity。如果写入了一些数据以后,想从头开始读的话,这时候的limit应该就是当前ByteBuffer中数据的总长度。下面的这个图比较直观地说明了这个问题:
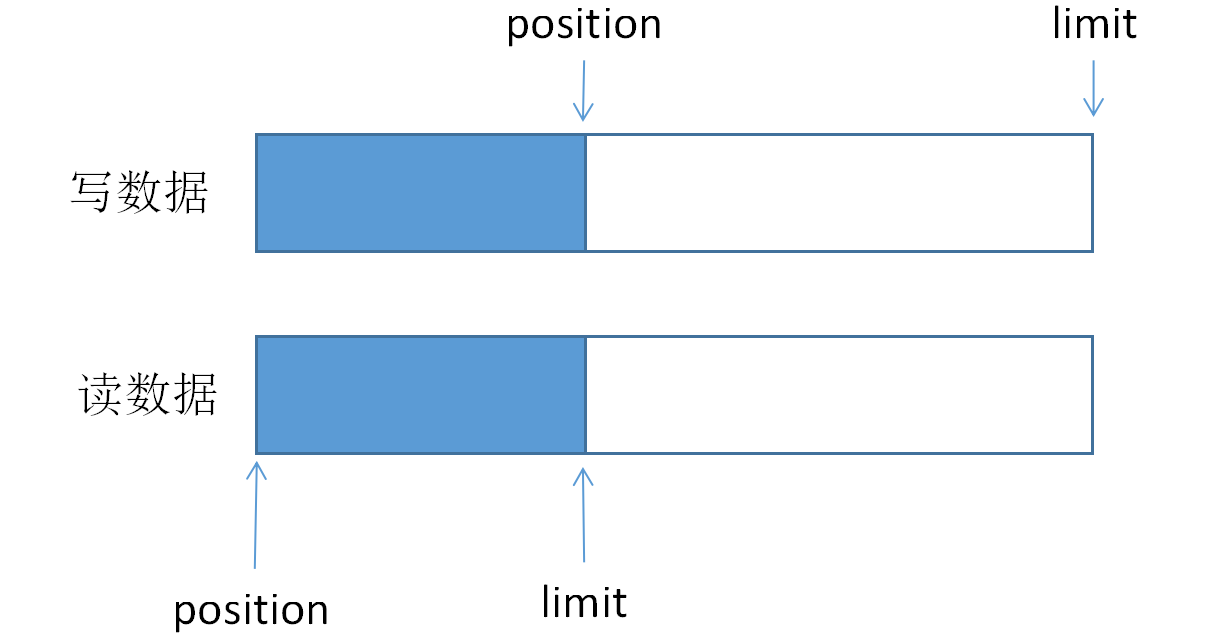
为了达到从写数据的情况变成读数据的情况,还需要修改limit,这就要用到limit方法:
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
我们可以这样写,就把byteBuffer从读变成写了:
byteBuffer.limit(byteBuffer.position())
byteBuffer.position(0);
当然,由于这个操作非常频繁,jdk就为我们封装了一个这样的方法,叫做flip:
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
使用这个反转方法,思路一定要清晰,稍有不慎,就会带来莫名其妙的错误,比如,连续调用flip会对ByteBuffer有什么样的影响呢?这其实会使得Buffer的limit变成0,从而既不能读也不能写了。
limit的设计确实可以加速数据溢出情况的检查,但是造成使用上和理解上的困难,我还是觉得得不偿失。我一直觉得limit这个设计很蠢(个人意见,如果有误,请各位指正)。
缓冲区标记
今天最后一个内容,是讲一下mark的作用。在理解了position的作用以后,mark就很容易理解了,它就是记住当前的位置用的:
public final Buffer mark() {
mark = position;
return this;
}
我们在调用过mark以后,再进行缓冲区的读写操作,position就会发生变化,为了再回到当初的位置,我们可以调用reset方法恢复position的值:
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
channel
NIO中通过channel封装了对数据源的操作,通过 channel 我们可以操作数据源,但又不必关心数据源的具体物理结构。
这个数据源可能是多种的。比如,可以是文件,也可以是网络socket。在大多数应用中,channel 与文件描述符或者 socket 是一一对应的。
在Java IO中,基本上可以分为文件类和Stream类两大类。Channel 也相应地分为了FileChannel 和 Socket Channel,其中 socket channel 又分为三大类,一个是用于监听端口的ServerSocketChannel,第二类是用于TCP通信的SocketChannel,第三类是用于UDP通信的DatagramChannel。
可以认为每建立一个channel就是建立了一个socket链接。
Channel的作用
channel 最主要的作用还是用于非阻塞式读写。这一条我们以后会讲,今天,主要看一下如何使用Channel进行编程。
Channel可以使用 ByteBuffer 进行读写,这是它的一个方便之处。我们先看一个例子,这个例子中,创建了一个ServerSocketChannel 并且在本机的8000端口上进行监听。可以看到,bind, listen这些操作,可以猜想到SocketChannel的具体实现,本质上也是对socket的一种封装而已。
public class WebServer {
public static void main(String args[]) {
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress("127.0.0.1", 8000));
SocketChannel socketChannel = ssc.accept();
ByteBuffer readBuffer = ByteBuffer.allocate(128);
socketChannel.read(readBuffer);
readBuffer.flip();
while (readBuffer.hasRemaining()) {
System.out.println((char)readBuffer.get());
}
socketChannel.close();
ssc.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}
用静态的 open( )工厂方法创建一个新的 ServerSocketChannel 对象,将会返回同一个未绑定的 java.net.ServerSocket 关联的通道。这个相关联的 ServerSocket 可以通过在 ServerSocketChannel 上调用 socket( )方法来获取。我们在这个例子中,使用了socket().bind来实现socket的绑定。
bind方法,监听这个端口上的所有coming的socket链接,源码里bind实际上是调用了Linux bind listen两个函数。
accept方法,源码调用了Linux的accept函数,会阻塞当前线程,直到有socket链接coming。
read方法,源码调用了Linux的read函数,会阻塞当前线程,直到socket有数据发送过来。
客户端代码:
public class WebClient {
public static void main(String[] args) {
SocketChannel socketChannel = null;
try {
socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 8000));
ByteBuffer writeBuffer = ByteBuffer.allocate(128);
writeBuffer.put("hello world".getBytes());
writeBuffer.flip();
socketChannel.write(writeBuffer);
socketChannel.close();
} catch (IOException e) {
}
}
}
新创建的 SocketChannel 虽已打开却是未连接的。在一个未连接的 SocketChannel 对象上尝试一 个 I/O 操作会导致 NotYetConnectedException 异常。我们可以通过在通道上直接调用 connect() 方法或在通道关联的 Socket 对象上调用 connect()来实现socket的连接。一旦一个 socket 通道被连接,它将保持连接状态直到被关闭。我们可以通过调用 isConnected()方法来测试某个 SocketChannel 是否已连接。
本节课程所使用的ByteBuffer上一课也有讲解,如果对flip,get, put 等操作还是感到不理解的,可以去查看上一节课程。
先运行服务端,再运行客户端,所得到的结果如下:
就是说,我们把客户端发送过来的字符串逐字符地打印出来了。
其实,熟悉Java IO的读者都知道,我们同样可以使用InputStream和OutputStream进行字节流的读写,而且看起来,ByteBuffer似乎还没有直接使用byte[] 进行读写来得直观。实际上,channel 最大的作用并不仅限于此,它的最大作用是封装了异步操作,后面我会在 selector 的地方详细解释。
Scatter / Gather
Channel 提供了一种被称为 Scatter/Gather 的新功能,也称为本地矢量 I/O。Scatter/Gather 是指在多个缓冲区上实现一个简单的 I/O 操作。对于一个 write 操作而言,数据是从几个缓冲区(通常就是一个缓冲区数组)按顺序抽取(称为 gather)并使用 channel 发送出去。缓冲区本身并不需要具备这种 gather 的能力。gather 过程等效于全部缓冲区的内容被连结起来,并在发送数据前存放到一个大的缓冲区中。对于 read 操作而言,从 通道读取的数据会按顺序被散布(称为 scatter)到多个缓冲区,将每个缓冲区填满直至通道中的数据或者缓冲区的最大空间被消耗完。
大多数现代操作系统都支持本地矢量 I/O(native vectored I/O)。我们在一个通道上发起一个 Scatter/Gather 操作时,该请求会被翻译为适当的本地调用来直接填充或抽取缓冲区。这是一个很大的进步,因为减少或避免了缓冲区拷贝和系统调用。Scatter/Gather 应该使用直接的 ByteBuffers 以从本地 I/O 获取最大性能优势。
例如,我们可以把客户端改写成这个样子:
public class WebClient {
public static void main(String[] args) {
SocketChannel socketChannel = null;
try {
socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 8000));
ByteBuffer writeBuffer = ByteBuffer.allocate(128);
ByteBuffer buffer2 = ByteBuffer.allocate(16);
writeBuffer.put("hello ".getBytes());
buffer2.put("world".getBytes());
writeBuffer.flip();
buffer2.flip();
ByteBuffer[] bufferArray = {writeBuffer, buffer2};
socketChannel.write(bufferArray);
socketChannel.close();
} catch (IOException e) {
}
}
}
这样就实现了一个Gather IO。Gather IO 在现在还看不出来有什么作用。我们后面会看到,在并发场景下,这是一个非常好用的特性。
阻塞式io
这里直接略过了,因为上面的例子就是阻塞式io
socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("192.168.0.13", 8000));
System.out.println("Hello");
你会看到,在connect没有完成之前,最后第三行的println根本不会执行。也就是说客户端会阻塞在这个地方。
非阻塞式io
在Java中要使用非阻塞非常简单,只需要在socketChannel上调用:
socketChannel.configureBlocking(false);
public class NetClient {
public static void main(String[] args) {
try {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 8001));
socketChannel.configureBlocking(false);
ByteBuffer writeBuffer = ByteBuffer.allocate(1024);
writeBuffer.put("hello world!".getBytes());
writeBuffer.flip();
socketChannel.write(writeBuffer);
socketChannel.close();
} catch (IOException e) {
}
}
}
可以看到服务端没啥变化,实际上我们也可以把服务端改造成非阻塞,但这样就会因为buffer中收不到数据而抛出空指针异常。
所以这里我们先不改造服务端,接着下面说
io多路复用
引入多路复用的原因
实际上,在服务端与客户端一对一通信的时候,同步阻塞式地读写并不会有太大的问题,最典型的就是两个对等机器之间建立了TCP连接,并且通过TCP连接来发送一个大文件,有大量的数据传输。在这种场景中,阻塞式的写法简单高效。
但是,在服务器场景下,例如,一个 Web Server,它的特点是客户端很多,连接时间很短,数据发送量很小(一个网页几十到几百K),为了让每一个用户都能得到及时的响应,我们可以使用多线程的方式来实现服务端,例如这节课的例子:多线程服务端。
但是,一台服务器能创建的线程数是十分有限的,在Java中创建线程,一个线程默认就会预留1M的空间,那么1G的内存也不过只能支持1000个线程创建而已。而且,随着线程数的增多,线程之间的调度和切换,引发的资源竞争也会加剧,使整个系统变得很慢。
这个问题的最佳解决方案,就是select 和 epoll/poll。
Selector
在Java中,Selector这个类是select/epoll/poll的外包类,在不同的平台上,底层的实现可能有所不同,但其基本原理是一样的,其原理图如下所示:
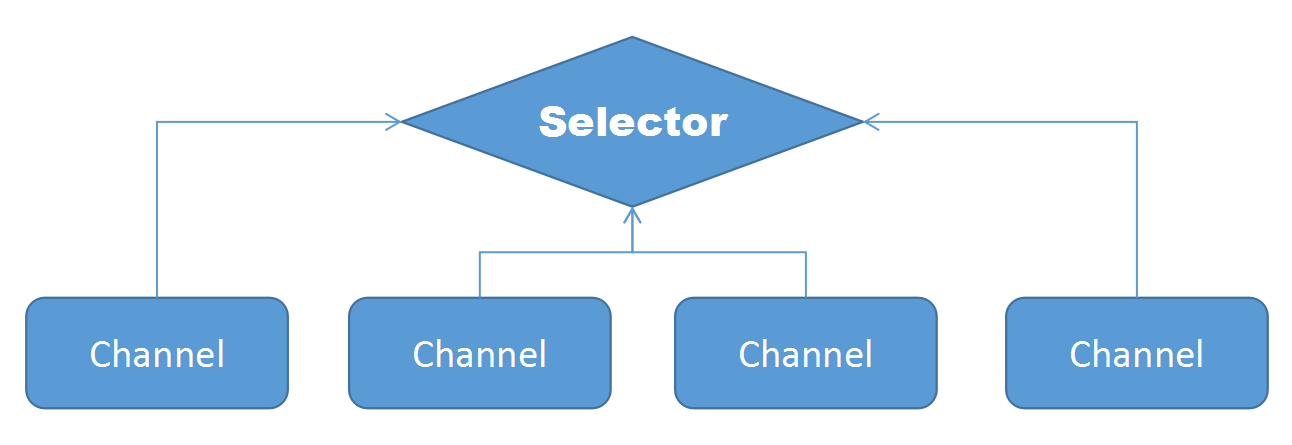
所有的Channel都归Selector管理,这些channel中只要有至少一个有IO动作,就可以通过Selector.select方法检测到,并且使用selectedKeys得到这些有IO的channel,然后对它们调用相应的IO操作。
我这里有一个服务端的例子:
public class EpollServer {
public static void main(String[] args) {
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress("127.0.0.1", 8000));
// 设置为非阻塞
ssc.configureBlocking(false);
Selector selector = Selector.open();
// 将selector和Channel绑定,并为该Channel注册SelectionKey.OP_ACCEPT事件,注册该事件后,
// 当该事件到达时,selector.select()会返回,如果该事件没到达selector.select()会一直阻塞。
ssc.register(selector, SelectionKey.OP_ACCEPT);
// 设置读写buffer
ByteBuffer readBuff = ByteBuffer.allocate(1024);
ByteBuffer writeBuff = ByteBuffer.allocate(128);
writeBuff.put("received".getBytes());
writeBuff.flip();
// 采用轮询的方式监听selector上是否有需要处理的事件,如果有,则进行处理
while (true) {
// 当注册的事件到达时,方法返回;否则,该方法会一直阻塞
selector.select();
// 获得selector中选中的项的迭代器,选中的项为注册的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> it = keys.iterator();
while (it.hasNext()) {
SelectionKey key = it.next();
// 删除已选的key,以防重复处理
it.remove();
// 获得了客户端请求连接事件
if (key.isAcceptable()) {
// 获得和客户端连接的通道
SocketChannel socketChannel = ssc.accept();
// 设为非阻塞
socketChannel.configureBlocking(false);
// 把连接注册到selector上,而且,
// 声明这个channel只对读操作感兴趣。
socketChannel.register(selector, SelectionKey.OP_READ);
}
// 获得了可读的事件
else if (key.isReadable()) {
// 得到事件发生的Socket channel
SocketChannel socketChannel = (SocketChannel) key.channel();
readBuff.clear();
socketChannel.read(readBuff);
readBuff.flip();
System.out.println("received : " + Charset.forName("utf-8").decode(readBuff).toString());
key.interestOps(SelectionKey.OP_WRITE);
}
// 获得了写的事件
else if (key.isWritable()) {
writeBuff.rewind();
// 得到事件发生的Socket channel
SocketChannel socketChannel = (SocketChannel) key.channel();
// 向channel写入buffer
socketChannel.write(writeBuff);
// 告诉selector我们只对读感兴趣
key.interestOps(SelectionKey.OP_READ);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
这个例子的关键点:
- 创建一个ServerSocketChannel,和一个Selector,并且把这个server channel 注册到 selector上,注册的时间指定,这个channel 所感觉兴趣的事件是 SelectionKey.OP_ACCEPT,这个事件代表的是有客户端发起TCP连接请求。
- 使用 select 方法阻塞住线程,当select 返回的时候,线程被唤醒。再通过selectedKeys方法得到所有可用channel的集合。
- 遍历这个集合,如果其中channel 上有连接到达,就接受新的连接,然后把这个新的连接也注册到selector中去。
- 如果有channel是读,那就把数据读出来,并且把它感兴趣的事件改成写。如果是写,就把数据写出去,并且把感兴趣的事件改成读。
客户端:
public class EpollClient {
public static void main(String[] args) {
try {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 8000));
ByteBuffer writeBuffer = ByteBuffer.allocate(32);
ByteBuffer readBuffer = ByteBuffer.allocate(32);
writeBuffer.put("hello".getBytes());
writeBuffer.flip();
while (true) {
writeBuffer.rewind();
socketChannel.write(writeBuffer);
readBuffer.clear();
socketChannel.read(readBuffer);
}
} catch (IOException e) {
}
}
}
这个客户端不断地向服务端发送”hello”,并且从服务端接收”received”。
大家多启几个客户端程序,去连接同一个服务端,观察一下现象,动手改一下客户端代码,让它发送的更丰富一点,不要让每一个客户端发的都一样。
详解selector使用
创建Selector
Selector对象是通过调用静态工厂方法open()来实例化的,如下:
Selector Selector=Selector.open();
类方法open()实际上向SPI发出请求,通过默认的SelectorProvider对象获取一个新的实例。
将Channel注册到Selector
要实现Selector管理Channel,需要将channel注册到相应的Selector上,如下:
channel.configureBlocking(false);
SelectionKey key= channel.register(selector,SelectionKey,OP_READ);
通过调用通道的register()方法会将它注册到一个选择器上。与Selector一起使用时,Channel必须处于非阻塞模式下,否则将抛出IllegalBlockingModeException异常,这意味着不能将FileChannel与Selector一起使用,因为FileChannel不能切换到非阻塞模式,而套接字通道都可以。另外通道一旦被注册,将不能再回到阻塞状态,此时若调用通道的configureBlocking(true)将抛出BlockingModeException异常。
register()方法的第二个参数是“interest集合”,表示选择器所关心的通道操作,它实际上是一个表示选择器在检查通道就绪状态时需要关心的操作的比特掩码。比如一个选择器对通道的read和write操作感兴趣,那么选择器在检查该通道时,只会检查通道的read和write操作是否已经处在就绪状态。
它有以下四种操作类型:
- Connect 连接
- Accept 接受
- Read 读
- Write 写
需要注意并非所有的操作在所有的可选择通道上都能被支持,比如ServerSocketChannel支持Accept,而SocketChannel中不支持。我们可以通过通道上的validOps()方法来获取特定通道下所有支持的操作集合。
JAVA中定义了四个常量来表示这四种操作类型:
SelectionKey.OP_CONNECT
SelectionKey.OP_ACCEPT
SelectionKey.OP_READ
SelectionKey.OP_WRITE
如果Selector对通道的多操作类型感兴趣,可以用“位或”操作符来实现:int interestSet=SelectionKey.OP_READ|SelectionKey.OP_WRITE;
当通道触发了某个操作之后,表示该通道的某个操作已经就绪,可以被操作。因此,某个SocketChannel成功连接到另一个服务器称为“连接就绪”(OP_CONNECT)。一个ServerSocketChannel准备好接收新进入的连接称为“接收就绪”(OP_ACCEPT)。一个有数据可读的通道可以说是“读就绪”(OP_READ)。等待写数据的通道可以说是“写就绪”(OP_WRITE)。
我们注意到register()方法会返回一个SelectionKey对象,我们称之为键对象。该对象包含了以下四种属性:
- interest集合
- read集合
- Channel
- Selector
interest集合是Selector感兴趣的集合,用于指示选择器对通道关心的操作,可通过SelectionKey对象的interestOps()获取。最初,该兴趣集合是通道被注册到Selector时传进来的值。该集合不会被选择器改变,但是可通过interestOps()改变。我们可以通过以下方法来判断Selector是否对Channel的某种事件感兴趣:
int interestSet=selectionKey.interestOps();
boolean isInterestedInAccept = (interestSet & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT;
这里有一个需要注意的点,很重要,就是 key.interestOps(SelectionKey.OP_WRITE); 不仅仅是转换关注的事件状态,还会主动的将当前channel的状态进行转换,如果不主动把channel关闭,写事件会无限的被触发!
为什么?这里涉及到一个边缘触发还是水平触发的问题,详见:https://www.jianshu.com/p/6bdee8cfee90
简单来说:
触发的方式有两种
- 水平触发(level-triggered,也被称为条件触发)LT: 只要满足条件,就触发一个事件(只要有数据没有被获取,内核就不断通知你)
- 边缘触发(edge-triggered)ET: 每当状态变化时,触发一个事件。
水平触发: - 对于读操作 :只要内核缓冲区内容不为空,LT模式返回读就绪。
- 对于写操作 :只要内核缓冲区还不满,LT模式会返回写就绪。
Java NIO属于水平触发,即条件触发
所以,如果read事件中buffer没被读完,也是会被重新触发的。
再说什么时候写入channel,我们可不可以直接在read事件中写入channel呢?经实测是可以的,但为什么最好不要这么做呢?
因为:
如果有channel在Selector上注册了SelectionKey.OP_WRITE事件,在调用selector.select();时,系统会检查内核写缓冲区是否可写(什么时候是不可写的呢,比如缓冲区已满,channel调用了shutdownOutPut等等),如果可写,selector.select();立即返回,随后进入key.isWritable()分支。
当然你在channel上可以直接调用write(…),也可以将数据发送出去,但这样不够灵活,而且可能浪费CPU。
详见:https://segmentfault.com/a/1190000017777939
所以正确用法:
要触发写事件,需要先向 selector 注册该通道的写事件,跟注册读事件一样,当底层写缓冲区有空闲就会触发写事件了,而一般来说底层的写缓冲区大部分都是空闲的。所以一般只要注册了写事件,就会立马触发了,为了避免 cpu 空转,在写操作完成后需要把写事件取消掉,然后下次再有写操作时重新注册写事件。
再说read集合:
read集合是通道已经就绪的操作的集合,表示一个通道准备好要执行的操作了,可通过SelctionKey对象的readyOps()来获取相关通道已经就绪的操作。它是interest集合的子集,并且表示了interest集合中从上次调用select()以后已经就绪的那些操作。(比如选择器对通道的read,write操作感兴趣,而某时刻通道的read操作已经准备就绪可以被选择器获知了,前一种就是interest集合,后一种则是read集合。)。JAVA中定义以下几个方法用来检查这些操作是否就绪:
//int readSet=selectionKey.readOps()
selectionKey.isAcceptable()
selectionKey.isConnectable()
selectionKey.isReadable()
selectionKey.isWritable()
这几个方法全都调用readyOps()方法
需要注意的是,通过相关的选择键的readyOps()方法返回的就绪状态指示只是一个提示,底层的通道在任何时候都会不断改变,而其他线程也可能在通道上执行操作并影响到它的就绪状态。另外,我们不能直接修改read集合。
取出SelectionKey所关联的Selector和Channel
通过SelectionKey访问对应的Selector和Channel:
Channel channel = selectionKey.channel();
Selector selector = selectionKey.selector();
取消SelectionKey对象
我们可以通过SelectionKey对象的cancel()方法来取消特定的注册关系。该方法调用之后,该SelectionKey对象将会被”拷贝”至已取消键的集合中,该键此时已经失效,但是该注册关系并不会立刻终结。在下一次select()时,已取消键的集合中的元素会被清除,相应的注册关系也真正终结。
所以SelectionKey到底谁什么?
我们可以把SelectionKey理解为epoll中的监视channel(socket)返回事件的一个监控对象,每当有一个channel注册到selector中时,就会有一个SelectionKey对象生成,通过SelectionKey我们可以得到当前channel中我们关心的事件的就绪列表,通过readyOps()方法得到已经就绪的channel后,我们通过其channel()方法来获取channel并向缓冲区读写数据。
为SelectionKey绑定附加对象
可以将一个或者多个附加对象绑定到SelectionKey上,以便容易的识别给定的通道。通常有两种方式:
- 在注册的时候直接绑定:
SelectionKey key=channel.register(selector,SelectionKey.OP_READ,theObject); - 在绑定完成之后附加:
selectionKey.attach(theObject);//绑定
绑定之后,可通过对应的SelectionKey取出该对象:selectionKey.attachment();
如果要取消该对象,则可以通过该种方式:selectionKey.attach(null);
需要注意的是如果附加的对象不再使用,一定要人为清除,因为垃圾回收器不会回收该对象,若不清除的话会成内存泄漏。
需要注意的是attachment并不是epoll中的方法,我们来看一下attachment的解释:
通常,我们需要将某个应用程序的特定数据与某个selectionKey相关联,例如表示http 状态的对象,我们在得到了一个读事件(一个http request)后,会首先将这个读事件进行解析,并把需要保存的数据和状态保存到attachment中,以供处理写事件时处理。在我们解析完读事件后,我们会继续调用interestOps()方法将其转换成写事件,并在写事件中得到这个attachment,并进行状态转换,写入channel返回。
ps:一个用nio实现的http server:https://cloud.tencent.com/developer/article/1109637
多个并发线程可安全地使用selectionKey。一般情况下,读取和写入 interest 集合的操作将与selector的某些操作保持同步。具体如何执行该同步与实现有关:在一般实现中,如果正在进行某个selector操作,那么读取或写入 interest 集合可能会无限期地阻塞;在高性能的实现中,可能只会暂时阻塞。无论在哪种情况下,selector操作将始终使用该操作开始时当前的 interest 集合值。
一个单独的通道可被注册到多个选择器中,有些时候我们需要通过isRegistered()方法来检查一个通道是否已经被注册到任何一个选择器上。 通常来说,我们并不会这么做。
原理和实现
先复习一下epoll的函数
//创建一个eventpoll,返回它的文件描述符,内有一颗红黑树,用来保存监听的socket
int epoll_create(int size);
//用来添加,删除以及修改监听的socket(修改红黑树的节点)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
//等待监听的socket返回,进行后续操作
//它的主体是ep_poll(),该函数在for循环中检查epitem(完成队列)中有没有已经完成的事件
//有的话就把结果返回
//没有的话调用schedule_timeout()进入休眠,直到进程被再度唤醒或者超时。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
实现Java nio版本epoll的核心逻辑就在Selector,Selector内封装了大部分epoll的操作。
先看一下Selector#open()
public static Selector open() throws IOException {
return SelectorProvider.provider().openSelector();
}
其实就是对应着不同os的SelectorProvider,这里以Linux下的EPollSelectorImpl为例:
// File descriptors used for interrupt
protected int fd0;
protected int fd1;
// The poll object
EPollArrayWrapper pollWrapper;
// Maps from file descriptors to keys
private Map<Integer,SelectionKeyImpl> fdToKey;
EPollSelectorImpl(SelectorProvider sp) throws IOException {
super(sp);
long pipeFds = IOUtil.makePipe(false);
fd0 = (int) (pipeFds >>> 32);
fd1 = (int) pipeFds;
try {
pollWrapper = new EPollArrayWrapper();
pollWrapper.initInterrupt(fd0, fd1);
fdToKey = new HashMap<>();
} catch (Throwable t) {
try {
FileDispatcherImpl.closeIntFD(fd0);
} catch (IOException ioe0) {
t.addSuppressed(ioe0);
}
try {
FileDispatcherImpl.closeIntFD(fd1);
} catch (IOException ioe1) {
t.addSuppressed(ioe1);
}
throw t;
}
}
void initInterrupt(int fd0, int fd1) {
outgoingInterruptFD = fd1;
incomingInterruptFD = fd0;
epollCtl(epfd, EPOLL_CTL_ADD, fd0, EPOLLIN);
}
EPollSelectorImpl构造函数完成:
- EPollArrayWrapper的构建,EpollArrayWapper将Linux的epoll相关系统调用封装成了native方法供EpollSelectorImpl使用。
- EPollArrayWrapper会初始化epoll的文件描述符,并构建了一个用于存放epoll_wait返回结果的epoll_event数组。
- 通过EPollArrayWrapper向epoll注册中断事件。fd0是incomingInterruptFD,fd1是outgoingInterruptFD,并调用Linux的epollCtl函数,并调用epoll_ctl, 添加这个epoll的文件描述符
- 初始化fdToKey:构建文件描述符-SelectionKeyImpl映射表,所有注册到selector的channel(socket)对应的SelectionKey和与之对应的文件描述符都会放入到该映射表中。
再来看serverChannel#register(selector, SelectionKey.OP_ACCEPT);
public final SelectionKey register(Selector sel, int ops,
Object att)
throws ClosedChannelException
{
synchronized (regLock) {
if (!isOpen())
throw new ClosedChannelException();
if ((ops & ~validOps()) != 0)
throw new IllegalArgumentException();
if (blocking)
throw new IllegalBlockingModeException();
SelectionKey k = findKey(sel);
if (k != null) {
k.interestOps(ops);
k.attach(att);
}
if (k == null) {
// New registration
synchronized (keyLock) {
if (!isOpen())
throw new ClosedChannelException();
k = ((AbstractSelector)sel).register(this, ops, att);
addKey(k);
}
}
return k;
}
}
protected final SelectionKey register(AbstractSelectableChannel ch,
int ops,
Object attachment)
{
if (!(ch instanceof SelChImpl))
throw new IllegalSelectorException();
SelectionKeyImpl k = new SelectionKeyImpl((SelChImpl)ch, this);
k.attach(attachment);
synchronized (publicKeys) {
implRegister(k);
}
k.interestOps(ops);
return k;
}
- 构建代表channel(socket)和selector间关系的SelectionKey对象
- implRegister(k)将channel(socket)注册到epoll中
- k.interestOps(int) 完成下面两个操作:
- 会将注册的感兴趣的事件和其对应的文件描述存储到EPollArrayWrapper对象的eventsLow或eventsHigh中,这是给底层实现epoll_wait时使用的。
- 同时该操作还会将设置SelectionKey的interestOps字段,这是给我们程序员获取使用的。
EPollSelectorImpl#implRegister
protected void implRegister(SelectionKeyImpl ski) {
if (closed)
throw new ClosedSelectorException();
SelChImpl ch = ski.channel;
int fd = Integer.valueOf(ch.getFDVal());
fdToKey.put(fd, ski);
pollWrapper.add(fd);
keys.add(ski);
}
- 将channel对应的fd(文件描述符)和对应的SelectionKeyImpl放到fdToKey映射表中。
- 将channel对应的fd(文件描述符)添加到EPollArrayWrapper中,并强制初始化fd的事件为0 ( 强制初始更新事件为0,因为该事件可能存在于之前被取消过的注册中。)
- 将selectionKey放入到keys集合中。
Selection操作
selection操作有3中类型:
- select():该方法会一直阻塞直到至少一个channel被选择(即,该channel注册的事件发生了)为止,除非当前线程发生中断或者selector的wakeup方法被调用。
- select(long time):该方法和select()类似,该方法也会导致阻塞直到至少一个channel被选择(即,该channel注册的事件发生了)为止,除非下面3种情况任意一种发生:
- 设置的超时时间到达;
- 当前线程发生中断;
- selector的wakeup方法被调用
- selectNow():该方法不会发生阻塞,如果没有一个channel被选择也会立即返回。
这里我们主要关注select()所调用的EPollSelectorImpl#doSelect方法
protected int doSelect(long timeout) throws IOException {
if (closed)
throw new ClosedSelectorException();
// 从cancelledKeys集合中依次取出注销的SelectionKey,执行注销操作
// 将处理后的SelectionKey从cancelledKeys集合中移除。
// 执行processDeregisterQueue()后cancelledKeys集合会为空。
// 这里会对EPollArrayWrapper进行操作,把这些不再关心的channel(socket)从EPollArrayWrapper的数据结构中移出,并修改fdToKey映射
// 注意直到这里,我们都还没有调用过epoll_ctl去对epoll中的红黑树进行修改,这里只是修改Java中保存的channel
processDeregisterQueue();
try {
begin();
// 看后面,这里实际上是会阻塞线程
pollWrapper.poll(timeout);
} finally {
end();
}
processDeregisterQueue();
// 通过EPollArrayWrapper pollWrapper 以及 fdToKey( 构建文件描述符-SelectorKeyImpl映射表 )来获取有事件触发的SelectionKeyImpl对象,
// 然后将SelectionKeyImpl放到selectedKey集合( 有事件触发的selectionKey集合,可以通过selector.selectedKeys()方法获得 )中,即selectedKeys。
// 并重新设置SelectionKeyImpl中相关的readyOps值。
int numKeysUpdated = updateSelectedKeys();
if (pollWrapper.interrupted()) {
// Clear the wakeup pipe
pollWrapper.putEventOps(pollWrapper.interruptedIndex(), 0);
synchronized (interruptLock) {
pollWrapper.clearInterrupted();
IOUtil.drain(fd0);
interruptTriggered = false;
}
}
return numKeysUpdated;
}
- 先处理注销的selectionKey队列
- 进行底层的epoll_wait操作
- 再次对注销的selectionKey队列进行处理
- 更新被选择的selectionKey
接着我们来看EPollArrayWrapper#poll(timeout):
int poll(long timeout) throws IOException {
updateRegistrations();
updated = epollWait(pollArrayAddress, NUM_EPOLLEVENTS, timeout, epfd);
for (int i=0; i<updated; i++) {
if (getDescriptor(i) == incomingInterruptFD) {
interruptedIndex = i;
interrupted = true;
break;
}
}
return updated;
}
- updateRegistrations()方法会将已经注册到该selector的事件(events, 就是SelectionKey的option,也是epoll中的epoll_events)通过调用epollCtl(epfd, opcode, fd, events); 注册到epoll的红黑树中
- 这里epollWait就会调用linux底层的epoll_wait方法,并返回在epoll_wait期间有事件触发的channel的个数
总结一下
Selector中封装了Linux epoll的操作,当调用selector.select();时,当前线程会阻塞(体现同步io操作),这个select方法实际上是调用epoll中的epoll_wait方法,来监听不同的channel(socket)是否有事件返回,通过一个selector线程来监听多个channel(socket),并且不用阻塞住channel(socket)(操作系统帮我们处理),这体现了非阻塞的概念。所以说,epoll是同步非阻塞的模型。(我的理解,实际上就是一个事件驱动的模型)
关于aio
看这里 https://www.pdai.tech/md/java/io/java-io-aio.html
简单来说,就是通过订阅-通知模式,由channel通道直接到操作系统注册监听,来监听多个channel上的数据,主线程不再阻塞。当操作系统发生IO事件,并且准备好数据后,在主动通知应用程序,触发相应的回调函数。使用“AsynchronousServerSocketChannel”(服务器监听通道)、“AsynchronousSocketChannel”(socket套接字通道)。
关于nio的堆外内存分配
如果说,我们使用普通的ByteBuffer,那么这个ByteBuffer就会在Java堆内,被JVM所管理:
ByteBuffer buf = ByteBuffer.allocate(1024);
当 buf 被JVM所管理时,它会在变成垃圾以后,自动被回收,这个不需要我们来操心。但它有个问题,后面会讲到,在执行GC的时候,JVM实际上会做一些整理内存的工作,也就说buf这个对象在内存中的实际地址是会发生变化的。有些时候,ByteBuffer里都是大量的字节,这些字节在JVM GC整理内存时就显得很笨重,把它们在内存中拷来拷去显然不是一个好主意。
那这时候,我们就会想能不能给我一块内存,可以脱离JVM的管理呢?在这样的背景下,就有了DirectBuffer。先看一下用法:
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
我们对比一下,allocate方法和allocateDirect方法就知道了:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
其中allocate中所创建的HeapByteBuffer刚好就是我们前边所介绍的,在堆里分配一个ByteBuffer,而DirectBuffer则是在堆外分配,使用了unsafe.allocateMemory来分配内存.
DirectBuffer优缺点
堆外内存的申请与普通的Java对象是有巨大的差别的。在以后的课程里,大家会发现,Java对象在Java堆里申请内存的时候,实际上是比malloc(堆外内存)要快的,所以DirectBuffer的创建效率往往是比Heap Buffer差的。
但是,如果进行网络读写或者文件读写的时候,DirectBuffer就会比较快了,说起来好笑,这个快是因为JDK故意把非DirectBuffer的读写搞慢的,我们看一下JDK的源代码。
share/classes/sun/nio/ch/IOUtil.java
static int write(FileDescriptor fd, ByteBuffer src, long position,
NativeDispatcher nd)
throws IOException
{
if (src instanceof DirectBuffer)
return writeFromNativeBuffer(fd, src, position, nd);
// Substitute a native buffer
int pos = src.position();
int lim = src.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
ByteBuffer bb = Util.getTemporaryDirectBuffer(rem);
try {
bb.put(src);
bb.flip();
// ................略
关键点在这个方法的第一行,如果src是DirectBuffer,就直接调用writeFromNativeBuffer,如果不是,则要先创建一个临时的DirectBuffer,把src拷进去,然后再调用真正的写操作。为什么要这么干呢?还是要从DirectBuffer不会被GC移动说起。
writeFromNativeBuffer的实现,最终会把Buffer的address传给操作系统,让操作系统把address开始的那一段内存发送到网络上。这就要求在操作系统进行发送的时候,这块内存是不能动的。而我们知道,GC是会乱搬Java堆里的东西的,所以无奈,我们必须得弄一块地址不会变化的内存,然后把这个地址发给操作系统。(回头再把这部分堆外内存给拿掉)
DirectBuffer当然还有一个直观的优点,不被GC管理,所以发生GC的时候,整理内存的压力就会小。当然,我后面也会讲,它并不是完全不被GC管理,它还是能被回收的,但是在GC平常整理内存的时候确实是不会去管它的。
堆外内存的管理,我在jvm的章节介绍过了。