kafka 基础

基本概念
- Topic
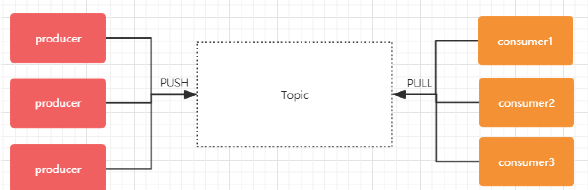
Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)。 - Producer
发布消息的对象称之为主题生产者(Kafka topic producer) - Consumer
订阅消息并处理发布的消息的对象称之为主题消费者(consumers) - Broker
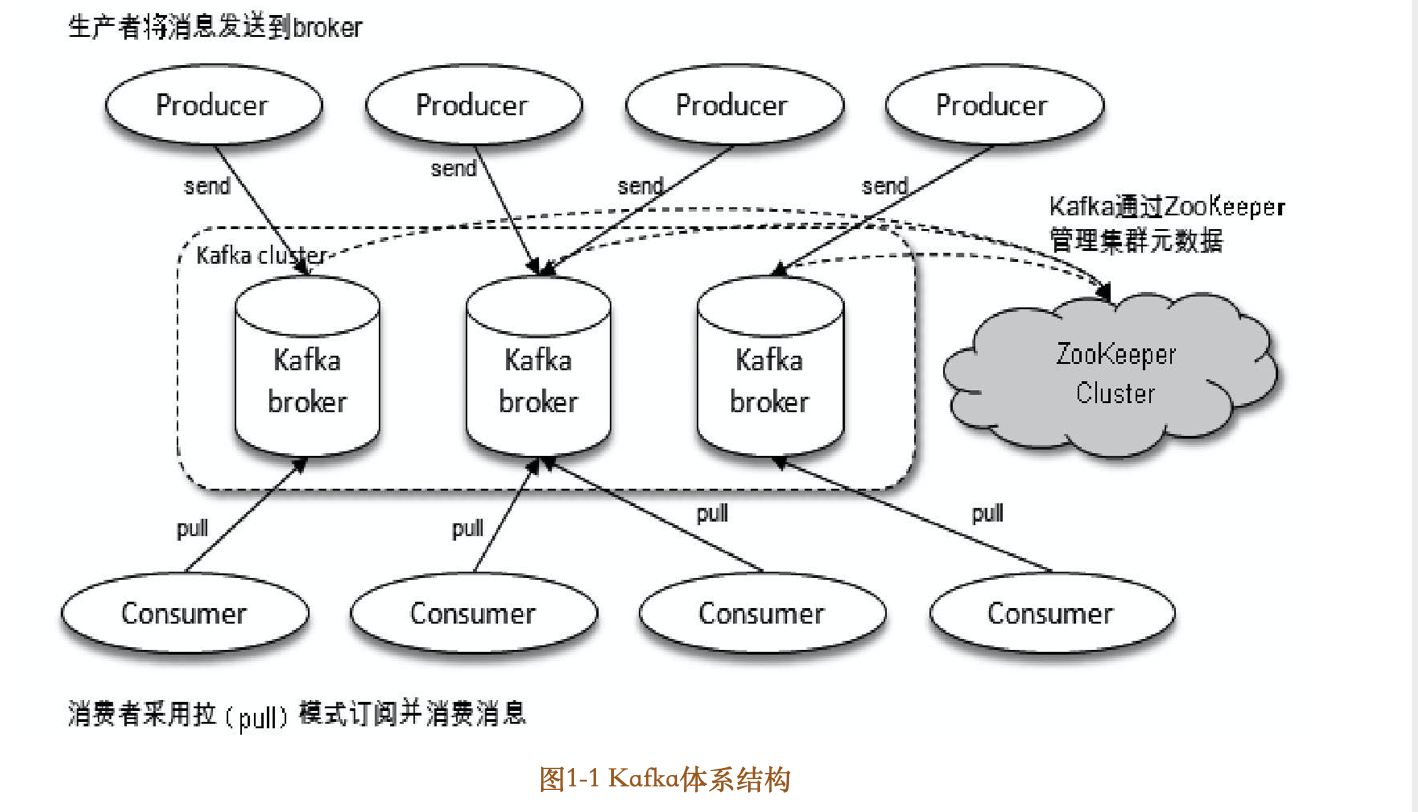
已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
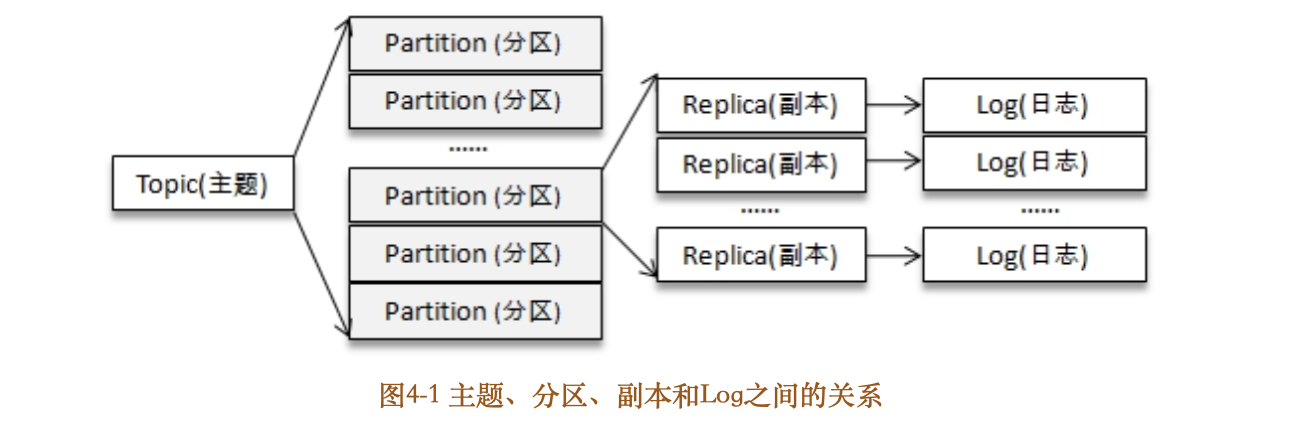
在 Kafka 中,Topic 是一个存储消息的逻辑概念,可以认为是一个消息集合。每条消息发送到 Kafka 集群的消息都有一个类别。物理上来说,不同的 Topic 的消息是分开存储的,每个 Topic 可以有多个生产者向它发送消息,也可以有多个消费者去消费其中的消息。
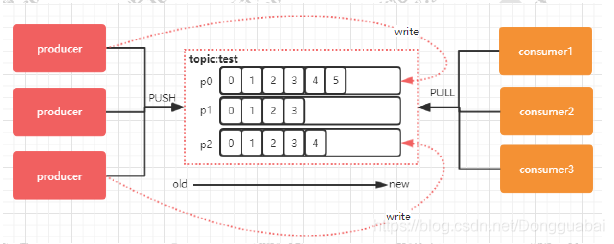
每个 Topic 可以划分多个分区(每个 Topic 至少有一个分区),同一 Topic 下的不同分区包含的消息是不同的。分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset),它是消息在此分区中的唯一编号,Kafka 通过 offset 保证消息在分区内的顺序,offset 的顺序不跨分区,即 Kafka 只保证在同一个分区内的消息是有序的。
消息是每次追加到对应的 Partition 的后面:
Kafka中的分区可以分布在不同的服务器(broker)上,也就是说,一个主题可以横跨多个broker,以此来提供比单个broker更强大的性能。
每一条消息被发送到broker之前,会根据分区规则选择存储到哪个具体的分区。如果分区规则设定得合理,所有的消息都可以均匀地分配到不同的分区中。如果一个主题只对应一个文件,那么这个文件所在的机器I/O将会成为这个主题的性能瓶颈,而分区解决了这个问题。在创建主题的时候可以通过指定的参数来设置分区的个数,当然也可以在主题创建完成之后去修改分区的数量,通过增加分区的数量可以实现水平扩展。
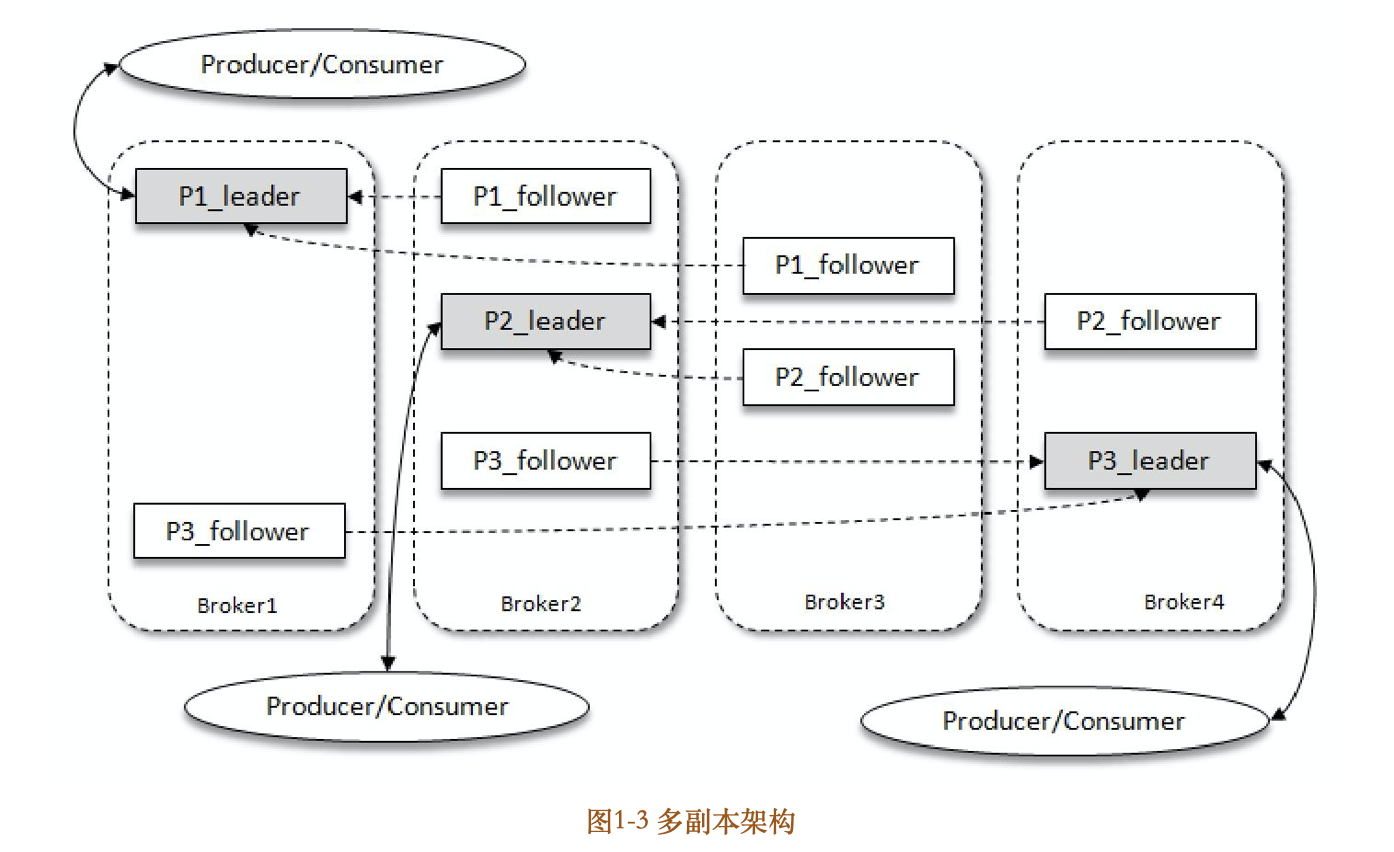
Kafka为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker失效时仍然能保证服务可用。
如图13所示,Kafka集群中有4个broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个leader副本和2个follower副本。生产者和消费者只与leader副本进行交互,而follower副本只负责消息的同步,很多时候follower副本中的消息相对leader副本而言会有一定的滞后。
Kafka消费端也具备一定的容灾能力。Consumer使用拉(Pull)模式从服务端拉取消息,并且保存消费的具体位置,当消费者宕机后恢复上线时可以根据之前保存的消费位置重新拉取需要的消息进行消费,这样就不会造成消息丢失。
分区中的所有副本统称为AR(AssignedReplicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(InSyncReplicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程度的同步”是指可忍受的滞后范围,这个范围可以通过参数进行配置。与leader副本同步滞后过多的副本(不包括leader副本)组成OSR(OutofSyncReplicas),由此可见,AR=ISR+OSR。在正常情况下,所有的follower副本都应该与leader副本保持一定程度的同步,即AR=ISR,OSR集合为空。
leader副本负责维护和跟踪ISR集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会把它从ISR集合中剔除。如果OSR集合中有follower副本“追上”了leader副本,那么leader副本会把它从OSR集合转移至ISR集合。默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader,而在OSR集合中的副本则没有任何机会(不过这个原则也可以通过修改相应的参数配置来改变)。
ISR与HW和LEO也有紧密的关系。HW是HighWatermark的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
如图14所示,它代表一个日志文件,这个日志文件中有9条消息,第一条消息的offset(LogStartOffset)为0,最后一条消息的offset为8,offset为9的消息用虚线框表示,代表下一条待写入的消息。日志文件的HW为6,表示消费者只能拉取到offset在0至5之间的消息,而offset为6的消息对消费者而言是不可见的。
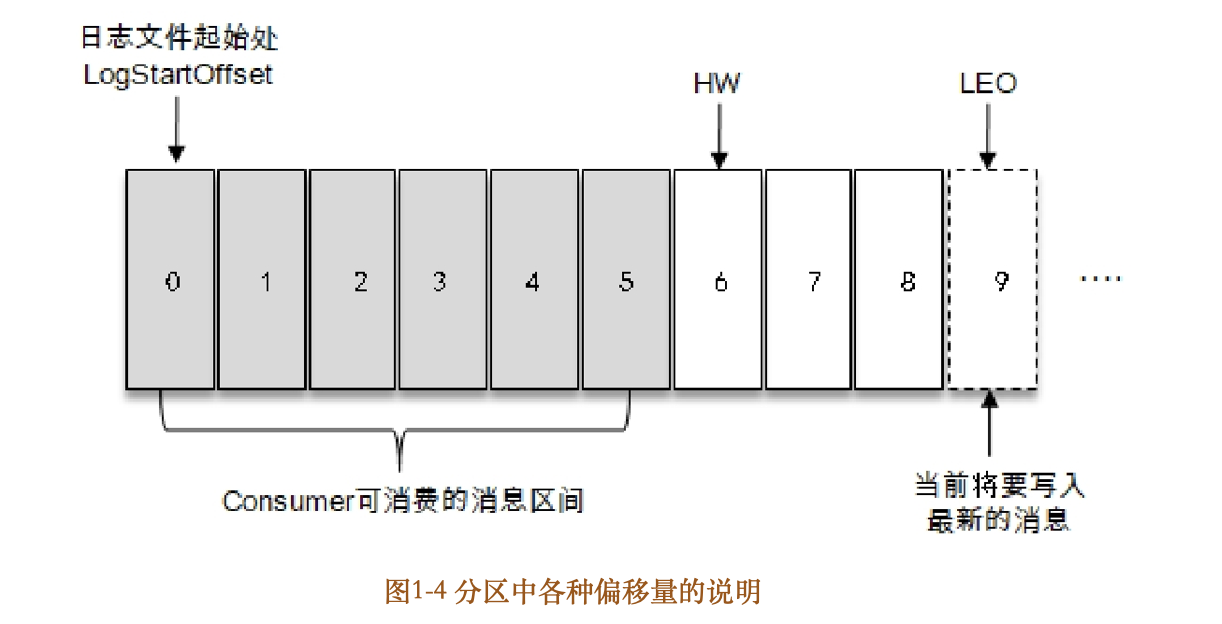
LEO是LogEndOffset的缩写,它标识当前日志文件中下一条待写入消息的offset,图14中offset为9的位置即为当前日志文件的LEO,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费者而言只能消费HW之前的消息。
注意要点:很多资料中误将图14中的offset为5的位置看作HW,而把offset为8的位置看作LEO,这显然是不对的。
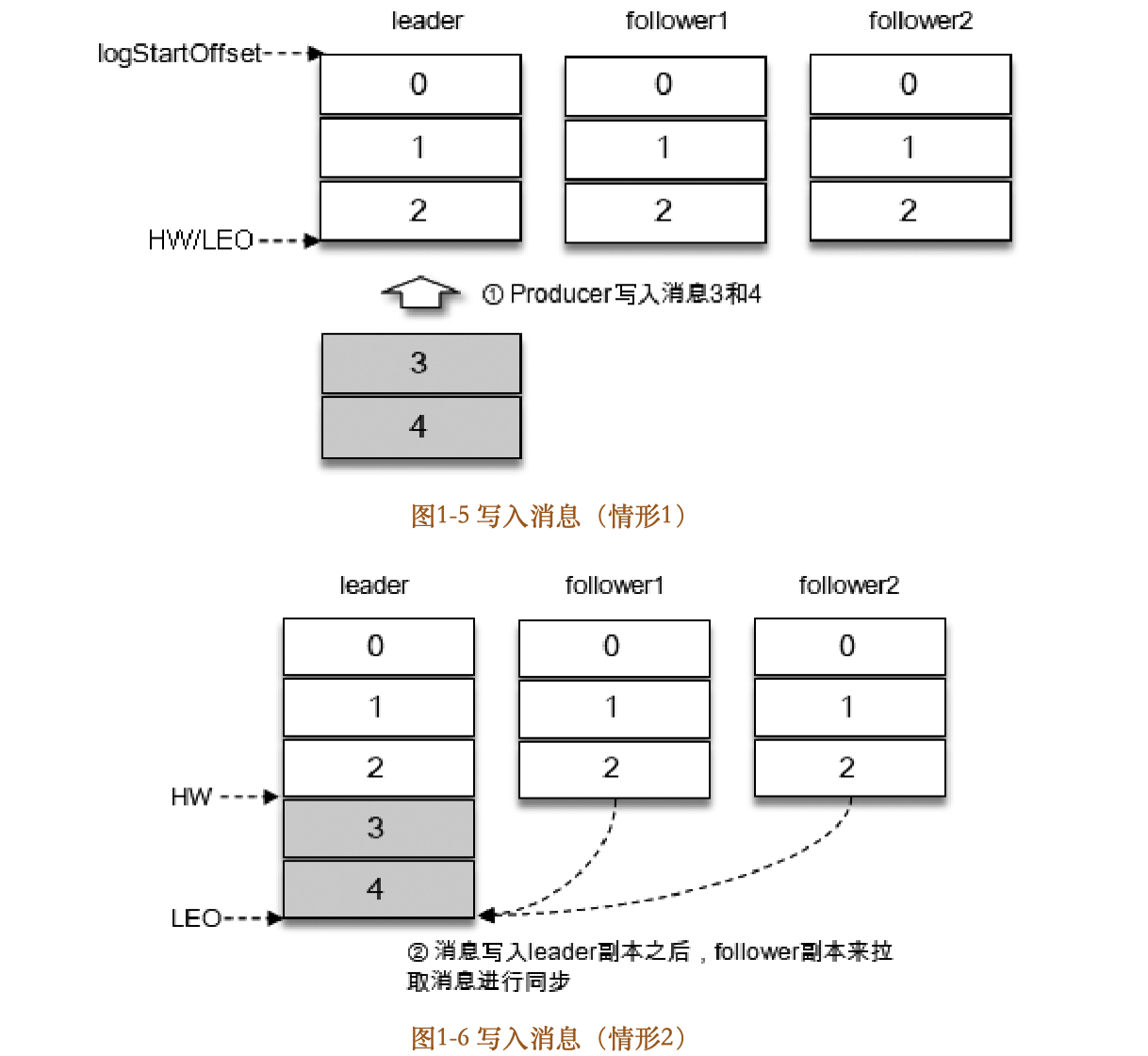
为了让读者更好地理解ISR集合,以及HW和LEO之间的关系,下面通过一个简单的示例来进行相关的说明。如图15所示,假设某个分区的ISR集合中有3个副本,即一个leader副本和2个follower副本,此时分区的LEO和HW都为3。消息3和消息4从生产者发出之后会被先存入leader副本,如图16所示。
在消息写入leader副本之后,follower副本会发送拉取请求来拉取消息3和消息4以进行消息同步。
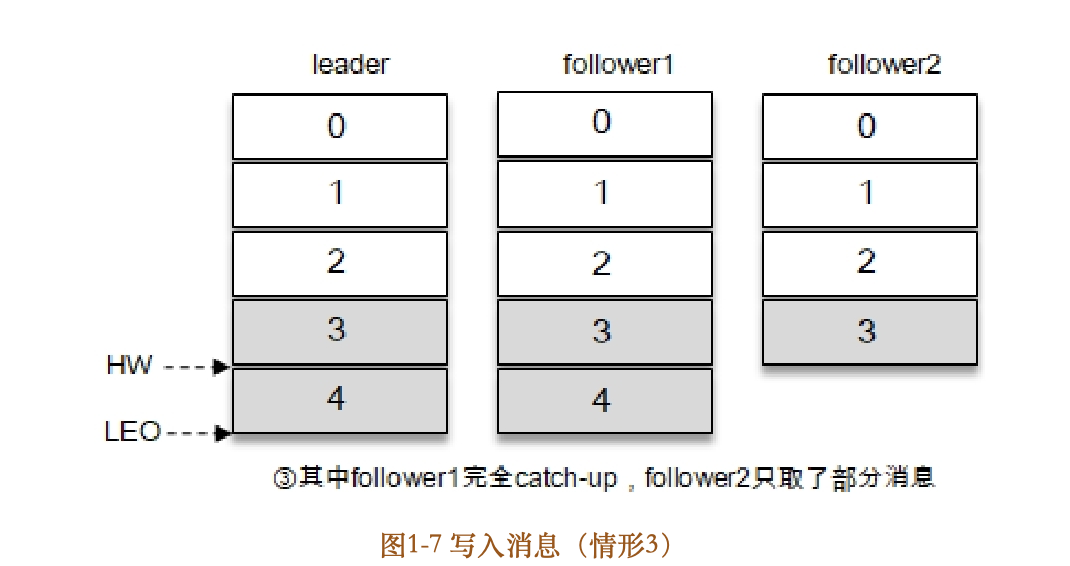
在同步过程中,不同的follower副本的同步效率也不尽相同。如图17所示,在某一时刻follower1完全跟上了leader副本而follower2只同步了消息3,如此leader副本的LEO为5,follower1的LEO为5,follower2的LEO为4,那么当前分区的HW取最小值4,此时消费者可以消费到offset为0至3之间的消息。
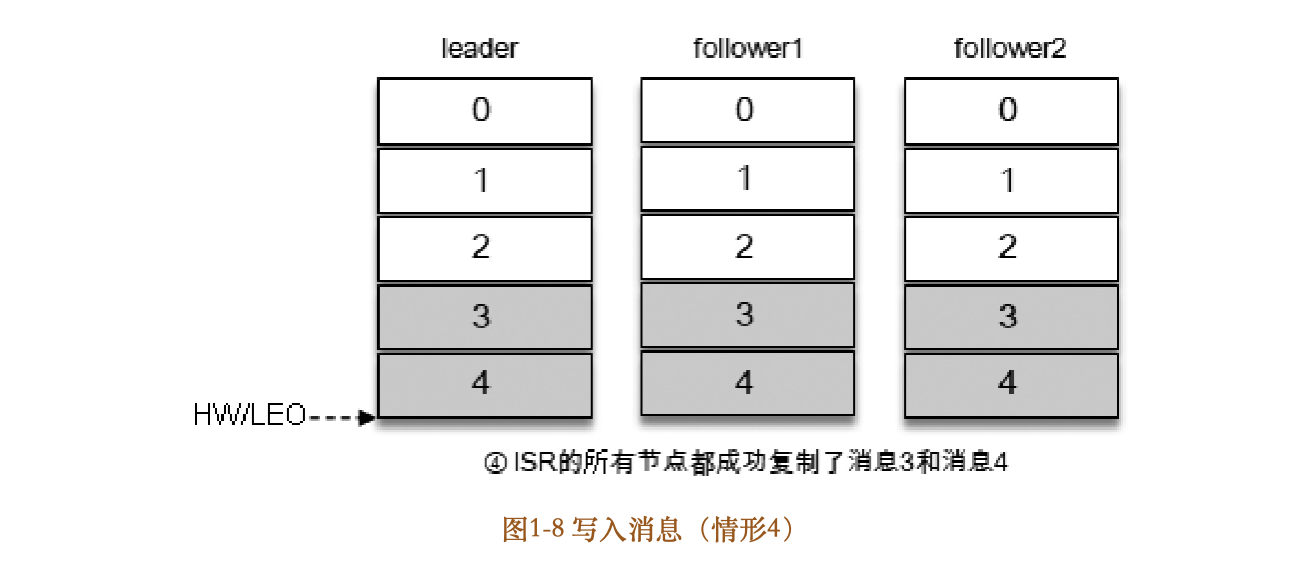
写入消息(情形4)如图18所示,所有的副本都成功写入了消息3和消息4,整个分区的HW和LEO都变为5,因此消费者可以消费到offset为4的消息了。
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower副本都复制完,这条消息才会被确认为已成功提交,这种复制方式极大地影响了性能。而在异步复制方式下,follower副本异步地从leader副本中复制数据,数据只要被leader副本写入就被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,突然leader副本宕机,则会造成数据丢失。Kafka使用的这种ISR的方式则有效地权衡了数据可靠性和性能之间的关系。
生产者
生产者客户端
//代码清单3-1 生产者客户端示例代码
public class KafkaProducerAnalysis {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static Properties initConfig(){
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("client.id", "producer.client.id.demo");
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record =
new ProducerRecord<>(topic, "Hello, Kafka!");
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
}
}
ProducerRecord,它并不是单纯意义上的消息,它包含了多个属性,原本需要发送的与业务相关的消息体只是其中的一个value属性,比如“Hello,Kafka!”只是ProducerRecord对象中的一个属性。ProducerRecord类的定义如下
public class ProducerRecord<K, V> {
private final String topic; //主题
private final Integer partition; //分区号
private final Headers headers; //消息头部
private final K key; //键
private final V value; //值
private final Long timestamp; //消息的时间戳
//省略其他成员方法和构造方法
}
其中topic和partition字段分别代表消息要发往的主题和分区号。headers字段是消息的头部,Kafka0.11.x版本才引入这个属性,它大多用来设定一些与应用相关的信息,如无需要也可以不用设置。key是用来指定消息的键,它不仅是消息的附加信息,还可以用来计算分区号进而可以让消息发往特定的分区。前面提及消息以主题为单位进行归类,而这个key可以让消息再进行二次归类,同一个key的消息会被划分到同一个分区中。有key的消息还可以支持日志压缩的功能。value是指消息体,一般不为空,如果为空则表示特定的消息—墓碑消息。timestamp是指消息的时间戳,它有CreateTime和LogAppendTime两种类型,前者表示消息创建的时间,后者表示消息追加到日志文件的时间。
发送消息主要有三种模式:发后即忘(fireandforget)、同步(sync)及异步(async)。
代码清单21中的这种发送方式就是发后即忘,它只管往Kafka中发送消息而并不关心消息是否正确到达。在大多数情况下,这种发送方式没有什么问题,不过在某些时候(比如发生不可重试异常时)会造成消息的丢失。这种发送方式的性能最高,可靠性也最差。
KafkaProducer的send()方法并非是void类型,而是Future<RecordMetadata>类型,send()方法有2个重载方法,具体定义如下:
public Future<RecordMetadata> send(ProducerRecord<K, V> record)
public Future<RecordMetadata> send(ProducerRecord<K, V> record,
Callback callback)
实际上send()方法本身就是异步的,send()方法返回的Future对象可以使调用方稍后获得发送的结果。示例中在执行send()方法之后直接链式调用了get()方法来阻塞等待Kafka的响应,直到消息发送成功,或者发生异常。如果发生异常,那么就需要捕获异常并交由外层逻辑处理。
我们再来了解一下异步发送的方式,一般是在send()方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。有读者或许会有疑问,send()方法的返回值类型就是Future,而Future本身就可以用作异步的逻辑处理。这样做不是不行,只不过Future里的get()方法在何时调用,以及怎么调用都是需要面对的问题,消息不停地发送,那么诸多消息对应的Future对象的处理难免会引起代码处理逻辑的混乱。使用Callback的方式非常简洁明了,Kafka有响应时就会回调,要么发送成功,要么抛出异常。异步发送方式的示例如下:
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
exception.printStackTrace();
} else {
System.out.println(metadata.topic() + "-" +
metadata.partition() + ":" + metadata.offset());
}
}
});
示例代码中遇到异常时(exception!=null)只是做了简单的打印操作,在实际应用中应该使用更加稳妥的方式来处理,比如可以将异常记录以便日后分析,也可以做一定的处理来进行消息重发。onCompletion()方法的两个参数是互斥的,消息发送成功时,metadata不为null而exception为null;消息发送异常时,metadata为null而exception不为null。
通常,一个KafkaProducer不会只负责发送单条消息,更多的是发送多条消息,在发送完这些消息之后,需要调用KafkaProducer的close()方法来回收资源。close()方法会阻塞等待之前所有的发送请求完成后再关闭KafkaProducer。
分区器
消息在通过send()方法发往broker的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用之后才能被真正地发往broker。拦截器(下一章会详细介绍)一般不是必需的,而序列化器是必需的。消息经过序列化之后就需要确定它发往的分区,如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。
如果消息ProducerRecord中没有指定partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值。分区器的作用就是为消息分配分区。
Kafka中提供的默认分区器是org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了org.apache.kafka.clients.producer.Partitioner接口,这个接口中定义了2个方法,具体如下所示。
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
public void close();
其中partition()方法用来计算分区号,返回值为int类型。partition()方法中的参数分别表示主题、键、序列化后的键、值、序列化后的值,以及集群的元数据信息,通过这些信息可以实现功能丰富的分区器。close()方法在关闭分区器的时候用来回收一些资源。
在默认分区器DefaultPartitioner的实现中,close()是空方法,而在partition()方法中定义了主要的分区分配逻辑。如果key不为null,那么默认的分区器会对key进行哈希(采用MurmurHash2算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同key的消息会被写入同一个分区。如果key为null,那么消息将会以轮询的方式发往主题内的各个可用分区。
注意:如果key不为null,那么计算得到的分区号会是所有分区中的任意一个;如果key为null,那么计算得到的分区号仅为可用分区中的任意一个,注意两者之间的差别。
在不改变主题分区数量的情况下,key与分区之间的映射可以保持不变。不过,一旦主题中增加了分区,那么就难以保证key与分区之间的映射关系了。除了使用Kafka提供的默认分区器进行分区分配,还可以使用自定义的分区器,只需同DefaultPartitioner一样实现Partitioner接口即可。默认的分区器在key为null时不会选择非可用的分区,我们可以通过自定义的分区器来打破这一限制。
生产者拦截器
Kafka一共有两种拦截器:生产者拦截器和消费者拦截器。本节主要讲述生产者拦截器的相关内容
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
生产者拦截器的使用也很方便,主要是自定义实现org.apache.kafka.clients.producer.ProducerInterceptor接口。ProducerInterceptor接口中包含3个方法:
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
public void close();
KafkaProducer在将消息序列化和计算分区之前会调用生产者拦截器的onSend()方法来对消息进行相应的定制化操作。一般来说最好不要修改消息ProducerRecord的topic、key和partition等信息,如果要修改,则需确保对其有准确的判断,否则会与预想的效果出现偏差。比如修改key不仅会影响分区的计算,同样会影响broker端日志压缩(LogCompaction)的功能。
KafkaProducer会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者拦截器的onAcknowledgement()方法,优先于用户设定的Callback之前执行。这个方法运行在Producer的I/O线程中,所以这个方法中实现的代码逻辑越简单越好,否则会影响消息的发送速度。
close()方法主要用于在关闭拦截器时执行一些资源的清理工作。在这3个方法中抛出的异常都会被捕获并记录到日志中,但并不会再向上传递。
原理
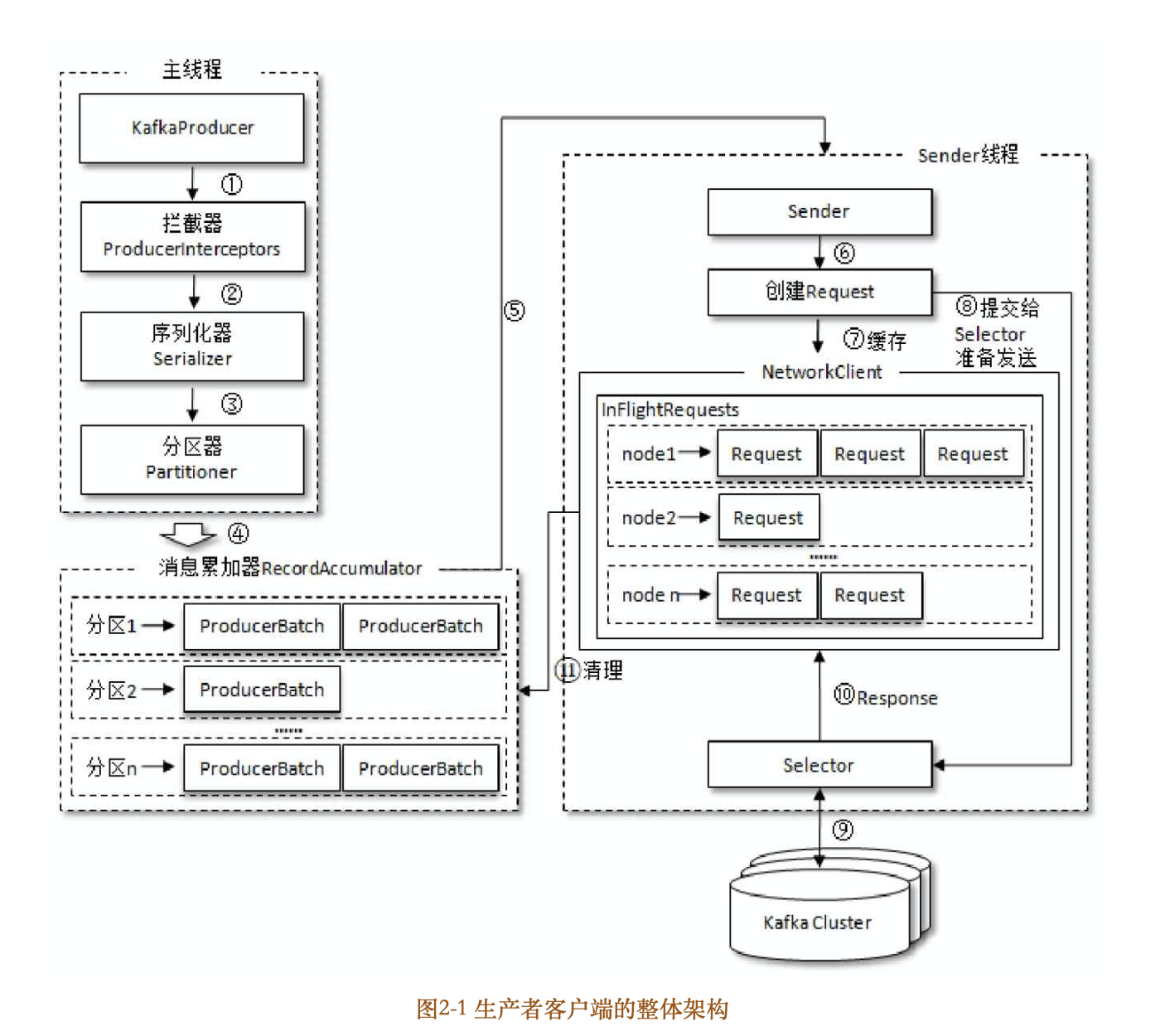
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程(发送线程)。在主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
消费者
消费者(Consumer)负责订阅Kafka中的主题(Topic),并且从订阅的主题上拉取消息。与其他一些消息中间件不同的是:在Kafka的消费理念中还有一层消费组(ConsumerGroup)的概念,每个消费者都有一个对应的消费组。当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者。
1个partition只能被同组的一个consumer消费,同组的consumer则起到均衡效果
- 如果所有的消费者都隶属于同一个消费组,那么所有的消息都会被均衡地投递给每一个消费者,即每条消息只会被一个消费者处理,这就相当于点对点模式的应用。
- 如果所有的消费者都隶属于不同的消费组,那么所有的消息都会被广播给所有的消费者,即每条消息会被所有的消费者处理,这就相当于发布/订阅模式的应用。
消费者多于partition
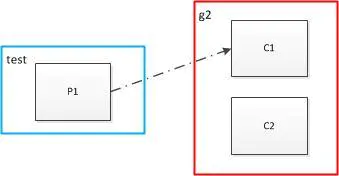
如上图,向test发送消息:1,2, 3,4,5,6,7,8,9
只有C1能接收到消息,C2则不能接收到消息,即同一个partition内的消息只能被同一个组中的一个consumer消费。当消费者数量多于partition的数量时,多余的消费者空闲。
也就是说如果只有一个partition你在同一组启动多少个consumer都没用,partition的数量决定了此topic在同一组中被可被均衡的程度,例如partition=4,则可在同一组中被最多4个consumer均衡消费。
消费者少于和等于partition
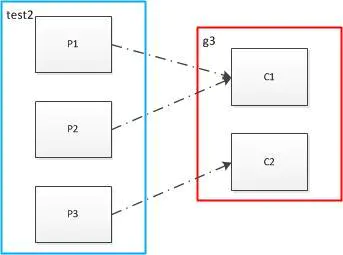
消费者数量2小于partition的数量3,此时,向test2发送消息1,2,3,4,5,6,7,8,9
C1接收到1,3,4,6,7,9
C2接收到2,5,8
此时P1、P2对对应C1,即多个partition对应一个消费者,C1接收到消息量是C2的两倍
然后,在g3组中再启动一个消费者,使得消费者数量为3等于topic2中partition的数量
此时,partition和消费者是一对一关系,向test2发送消息1,2,3,4,5,6,7,8,9
C1接收到了:2,5,8
C2接收到了:3,6,9
C3接收到了:1,4,7
C1,C2,C3均分了test2的所有消息,即消息在同一个组之间的消费者之间均分了!
多个消费者组
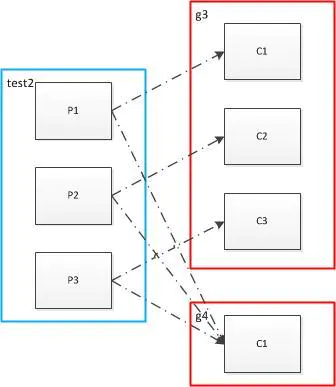
如上图,向test2发送消息1,2,3,4,5,6,7,8,9
消息被g3组的消费者均分,g4组的消费者在接收到了所有的消息。
g3组:
C1接收到了:2,5,8
C2接收到了:3,6,9
C3接收到了:1,4,7
g4组:
C1接收到了:1,2,3,4,5,6,7,8,9
启动多个组,则会使同一个消息被消费多次
消费者客户端
//代码清单8-1 消费者客户端示例
public class KafkaConsumerAnalysis {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
public static final AtomicBoolean isRunning = new AtomicBoolean(true);
public static Properties initConfig(){
Properties props = new Properties();
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("client.id", "consumer.client.id.demo");
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
try {
while (isRunning.get()) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic = " + record.topic()
+ ", partition = "+ record.partition()
+ ", offset = " + record.offset());
System.out.println("key = " + record.key()
+ ", value = " + record.value());
//do something to process record.
}
}
} catch (Exception e) {
log.error("occur exception ", e);
} finally {
consumer.close();
}
}
}
代码清单31中我们使用subscribe()方法订阅了一个主题,对于这个方法而言,既可以以集合的形式订阅多个主题,也可以以正则表达式的形式订阅特定模式的主题。subscribe的几个重载方法如下:
public void subscribe(Collection<String> topics,
ConsumerRebalanceListener listener)
public void subscribe(Collection<String> topics)
public void subscribe(Pattern pattern, ConsumerRebalanceListener listener)
public void subscribe(Pattern pattern)
对于消费者使用集合的方式(subscribe(Collection))来订阅主题而言,比较容易理解,订阅了什么主题就消费什么主题中的消息。如果前后两次订阅了不同的主题,那么消费者以最后一次的为准。
如果消费者采用的是正则表达式的方式(subscribe(Pattern))订阅,在之后的过程中,如果有人又创建了新的主题,并且主题的名字与正则表达式相匹配,那么这个消费者就可以消费到新添加的主题中的消息。如果应用程序需要消费多个主题,并且可以处理不同的类型,那么这种订阅方式就很有效。在Kafka和其他系统之间进行数据复制时,这种正则表达式的方式就显得很常见。正则表达式的方式订阅的示例如下:
consumer.subscribe(Pattern.compile("topic-.*"));
细心的读者可能观察到在subscribe的重载方法中有一个参数类型是ConsumerRebalanceListener,这个是用来设置相应的再均衡监听器的
消费者不仅可以通过KafkaConsumer.subscribe()方法订阅主题,还可以直接订阅某些主题的特定分区,在KafkaConsumer中还提供了一个assign()方法来实现这些功能,此方法的具体定义如下:
public void assign(Collection<TopicPartition> partitions)
这个方法只接受一个参数partitions,用来指定需要订阅的分区集合。
如果我们事先并不知道主题中有多少个分区怎么办?KafkaConsumer中的partitionsFor()方法可以用来查询指定主题的元数据信息。
public List<PartitionInfo> partitionsFor(String topic)
集合订阅的方式subscribe(Collection)、正则表达式订阅的方式subscribe(Pattern)和指定分区的订阅方式assign(Collection)分表代表了三种不同的订阅状态:AUTO_TOPICS、AUTO_PATTERN和USER_ASSIGNED(如果没有订阅,那么订阅状态为NONE)。然而这三种状态是互斥的,在一个消费者中只能使用其中的一种,否则会报出IllegalStateException异常
Kafka中的消费是基于拉模式的。消息的消费一般有两种模式:推模式和拉模式。推模式是服务端主动将消息推送给消费者,而拉模式是消费者主动向服务端发起请求来拉取消息。
Kafka中的消息消费是一个不断轮询的过程,消费者所要做的就是重复地调用poll()方法,而poll()方法返回的是所订阅的主题(分区)上的一组消息。
对于poll()方法而言,如果某些分区中没有可供消费的消息,那么此分区对应的消息拉取的结果就为空;如果订阅的所有分区中都没有可供消费的消息,那么poll()方法返回为空的消息集合。
poll()方法的具体定义如下:
public ConsumerRecords<K, V> poll(final Duration timeout)
注意到poll()方法里还有一个超时时间参数timeout,用来控制poll()方法的阻塞时间,在消费者的缓冲区里没有可用数据时会发生阻塞。
消费者消费到的每条消息的类型为ConsumerRecord(注意与ConsumerRecords的区别),这个和生产者发送的消息类型ProducerRecord相对应,不过ConsumerRecord中的内容更加丰富,具体的结构参考如下代码:
public class ConsumerRecord<K, V> {
private final String topic;
private final int partition;
private final long offset;
private final long timestamp;
private final TimestampType timestampType;
private final int serializedKeySize;
private final int serializedValueSize;
private final Headers headers;
private final K key;
private final V value;
private volatile Long checksum;
//省略若干方法
}
topic和partition这两个字段分别代表消息所属主题的名称和所在分区的编号。offset表示消息在所属分区的偏移量。timestamp表示时间戳,与此对应的timestampType表示时间戳的类型。timestampType有两种类型:CreateTime和LogAppendTime,分别代表消息创建的时间戳和消息追加到日志的时间戳。headers表示消息的头部内容。key和value分别表示消息的键和消息的值,一般业务应用要读取的就是value,比如使用2.1.3节中的CompanySerializer序列化了一个Company对象,然后将其存入Kafka,那么消费到的消息中的value就是经过CompanyDeserializer反序列化后的Company对象。serializedKeySize和serializedValueSize分别表示key和value经过序列化之后的大小,如果key为空,则serializedKeySize值为1。同样,如果value为空,则serializedValueSize的值也会为1。checksum是CRC32的校验值。
poll()方法的返回值类型是ConsumerRecords,它用来表示一次拉取操作所获得的消息集,内部包含了若干ConsumerRecord,它提供了一个iterator()方法来循环遍历消息集内部的消息
到目前为止,可以简单地认为poll()方法只是拉取一下消息而已,但就其内部逻辑而言并不简单,它涉及消费位移、消费者协调器、组协调器、消费者的选举、分区分配的分发、再均衡的逻辑、心跳等内容,在后面的章节中会循序渐进地介绍这些内容。
位移提交
在每次调用poll()方法时,它返回的是还没有被消费过的消息集(当然这个前提是消息已经存储在Kafka中了,并且暂不考虑异常情况的发生),要做到这一点,就需要记录上一次消费时的消费位移。并且这个消费位移必须做持久化保存,而不是单单保存在内存中,否则消费者重启之后就无法知晓之前的消费位移。再考虑一种情况,当有新的消费者加入时,那么必然会有再均衡的动作,对于同一分区而言,它可能在再均衡动作之后分配给新的消费者,如果不持久化保存消费位移,那么这个新的消费者也无法知晓之前的消费位移。
在旧消费者客户端中,消费位移是存储在ZooKeeper中的。而在新消费者客户端中,消费位移存储在Kafka内部的主题__consumer_offsets中。这里把将消费位移存储起来(持久化)的动作称为“提交”,消费者在消费完消息之后需要执行消费位移的提交。
参考图36的消费位移,x表示某一次拉取操作中此分区消息的最大偏移量,假设当前消费者已经消费了x位置的消息,那么我们就可以说消费者的消费位移为x,图中也用了lastConsumedOffset这个单词来标识它。
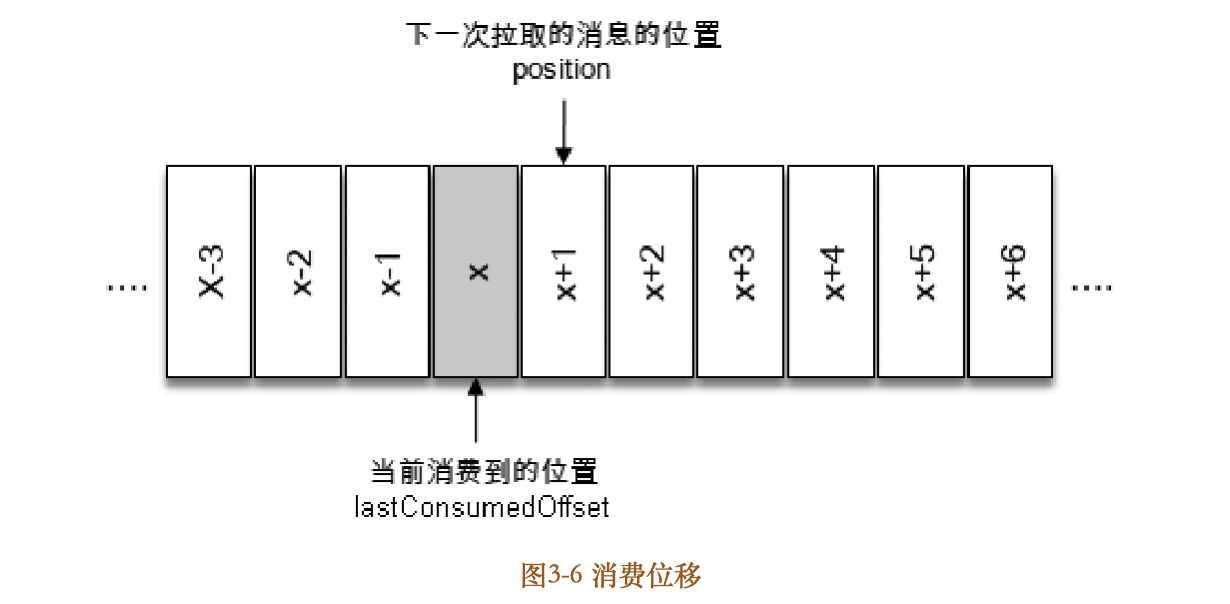
不过需要非常明确的是,当前消费者需要提交的消费位移并不是x,而是x+1
KafkaConsumer类提供了position(TopicPartition)和committed(TopicPartition)两个方法来分别获取上面所说的position和committedoffset的值。这两个方法的定义如下所示。
public long position(TopicPartition partition)
public OffsetAndMetadata committed(TopicPartition partition)
为了论证lastConsumedOffset、committedoffset和position之间的关系,我们使用上面的这两个方法来做相关演示。我们向某个主题中分区编号为0的分区发送若干消息,之后再创建一个消费者去消费其中的消息,等待消费完这些消息之后就同步提交消费位移(调用commitSync()方法,这个方法的细节在下面详细介绍),最后我们观察一下lastConsumedOffset、committedoffset和position的值。
//代码清单11-1 消费位移的演示
TopicPartition tp = new TopicPartition(topic, 0);
consumer.assign(Arrays.asList(tp));
long lastConsumedOffset = -1;//当前消费到的位移
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
if (records.isEmpty()) {
break;
}
List<ConsumerRecord<String, String>> partitionRecords
= records.records(tp);
lastConsumedOffset = partitionRecords
.get(partitionRecords.size() - 1).offset();
consumer.commitSync();//同步提交消费位移
}
System.out.println("comsumed offset is " + lastConsumedOffset);
OffsetAndMetadata offsetAndMetadata = consumer.committed(tp);
System.out.println("commited offset is " + offsetAndMetadata.offset());
long posititon = consumer.position(tp);
System.out.println("the offset of the next record is " + posititon);
示例中先通过assign()方法订阅了编号为0的分区,然后消费分区中的消息。示例中还通过调用ConsumerRecords.isEmpty()方法来判断是否已经消费完分区中的消息。
最终的输出结果如下:

可以看出,消费者消费到此分区消息的最大偏移量为377,对应的消费位移lastConsumedOffset也就是377。在消费完之后就执行同步提交,但是最终结果显示所提交的位移committedoffset为378,并且下一次所要拉取的消息的起始偏移量position也为378。在本示例中,position=committedoffset=lastConsumedOffset+1,当然position和committedoffset并不会一直相同,这一点会在下面的示例中有所体现。
对于位移提交的具体时机的把握也很有讲究,有可能会造成重复消费和消息丢失的现象。参考图37,当前一次poll()操作所拉取的消息集为[x+2,x+7],x+2代表上一次提交的消费位移,说明已经完成了x+1之前(包括x+1在内)的所有消息的消费,x+5表示当前正在处理的位置。如果拉取到消息之后就进行了位移提交,即提交了x+8,那么当前消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+8开始的。也就是说,x+5至x+7之间的消息并未能被消费,如此便发生了消息丢失的现象。
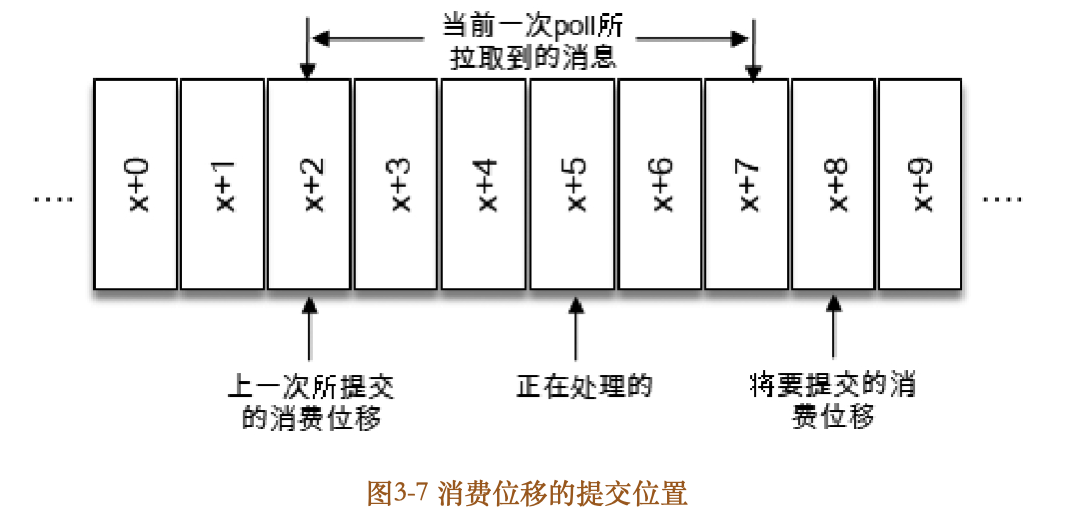
再考虑另外一种情形,位移提交的动作是在消费完所有拉取到的消息之后才执行的,那么当消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+2开始的。也就是说,x+2至x+4之间的消息又重新消费了一遍,故而又发生了重复消费的现象。
而实际情况还会有比这两种更加复杂的情形,比如第一次的位移提交的位置为x+8,而下一次的位移提交的位置为x+4,后面会做进一步的分析。
在Kafka中默认的消费位移的提交方式是自动提交,这个由消费者客户端参数enable.auto.commit配置,默认值为true。当然这个默认的自动提交不是每消费一条消息就提交一次,而是定期提交,这个定期的周期时间由客户端参数auto.commit.interval.ms配置,默认值为5秒,此参数生效的前提是enable.auto.commit参数为true。在代码清单31中并没有展示出这两个参数,说明使用的正是默认值。
在默认的方式下,消费者每隔5秒会将拉取到的每个分区中最大的消息位移进行提交。自动位移提交的动作是在poll()方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。
在Kafka消费的编程逻辑中位移提交是一大难点,自动提交消费位移的方式非常简便,它免去了复杂的位移提交逻辑,让编码更简洁。但随之而来的是重复消费和消息丢失的问题。假设刚刚提交完一次消费位移,然后拉取一批消息进行消费,在下一次自动提交消费位移之前,消费者崩溃了,那么又得从上一次位移提交的地方重新开始消费,这样便发生了重复消费的现象(对于再均衡的情况同样适用)。我们可以通过减小位移提交的时间间隔来减小重复消息的窗口大小,但这样并不能避免重复消费的发送,而且也会使位移提交更加频繁。
按照一般思维逻辑而言,自动提交是延时提交,重复消费可以理解,那么消息丢失又是在什么情形下会发生的呢?我们来看一下图38中的情形。拉取线程A不断地拉取消息并存入本地缓存,比如在BlockingQueue中,另一个处理线程B从缓存中读取消息并进行相应的逻辑处理。假设目前进行到了第y+1次拉取,以及第m次位移提交的时候,也就是x+6之前的位移已经确认提交了,处理线程B却还正在消费x+3的消息。此时如果处理线程B发生了异常,待其恢复之后会从第m此位移提交处,也就是x+6的位置开始拉取消息,那么x+3至x+6之间的消息就没有得到相应的处理,这样便发生消息丢失的现象。
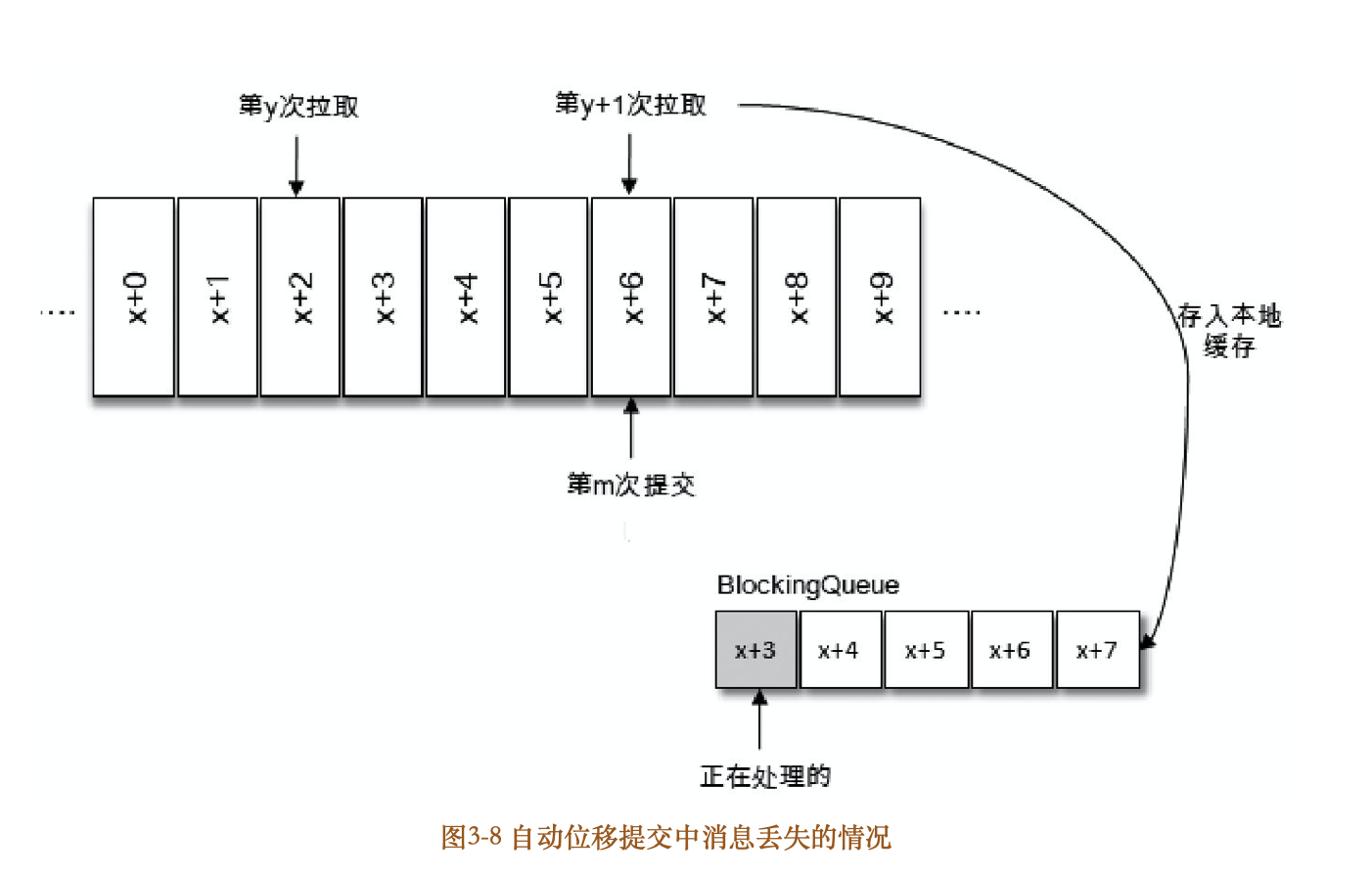
自动位移提交的方式在正常情况下不会发生消息丢失或重复消费的现象,但是在编程的世界里异常无可避免,与此同时,自动位移提交也无法做到精确的位移管理。在Kafka中还提供了手动位移提交的方式,这样可以使得开发人员对消费位移的管理控制更加灵活。很多时候并不是说拉取到消息就算消费完成,而是需要将消息写入数据库、写入本地缓存,或者是更加复杂的业务处理。在这些场景下,所有的业务处理完成才能认为消息被成功消费,手动的提交方式可以让开发人员根据程序的逻辑在合适的地方进行位移提交。开启手动提交功能的前提是消费者客户端参数enable.auto.commit配置为false。
手动提交可以细分为同步提交和异步提交,对应于KafkaConsumer中的commitSync()和commitAsync()两种类型的方法。我们这里先讲述同步提交的方式。
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
//do some logical processing.
}
consumer.commitSync();
}
上面的示例中将拉取到的消息存入缓存buffer,等到积累到足够多的时候,也就是示例中大于等于200个的时候,再做相应的批量处理,之后再做批量提交。这两个示例都有重复消费的问题,如果在业务逻辑处理完之后,并且在同步位移提交前,程序出现了崩溃,那么待恢复之后又只能从上一次位移提交的地方拉取消息,由此在两次位移提交的窗口中出现了重复消费的现象。
commitSync()方法会根据poll()方法拉取的最新位移来进行提交(注意提交的值对应于图36中position的位置),只要没有发生不可恢复的错误(UnrecoverableError),它就会阻塞消费者线程直至位移提交完成。
对于采用commitSync()的无参方法而言,它提交消费位移的频率和拉取批次消息、处理批次消息的频率是一样的,如果想寻求更细粒度的、更精准的提交,那么就需要使用commitSync()的另一个含参方法,具体定义如下:
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets)
该方法提供了一个offsets参数,用来提交指定分区的位移。无参的commitSync()方法只能提交当前批次对应的position值。如果需要提交一个中间值,比如业务每消费一条消息就提交一次位移,那么就可以使用这种方式
//代码清单11-2 带参数的同步位移提交
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
//do some logical processing.
long offset = record.offset();
TopicPartition partition =
new TopicPartition(record.topic(), record.partition());
consumer.commitSync(Collections
.singletonMap(partition, new OffsetAndMetadata(offset + 1)));
}
}
在实际应用中,很少会有这种每消费一条消息就提交一次消费位移的必要场景。commitSync()方法本身是同步执行的,会耗费一定的性能,而示例中的这种提交方式会将性能拉到一个相当低的点。更多时候是按照分区的粒度划分提交位移的界限,这里我们就要用到了3.2.4章中提及的ConsumerRecords类的partitions()方法和records(TopicPartition)方法
//代码清单11-3 按分区粒度同步提交消费位移
try {
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords =
records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
//do some logical processing.
}
long lastConsumedOffset = partitionRecords
.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition,
new OffsetAndMetadata(lastConsumedOffset + 1)));
}
}
} finally {
consumer.close();
}
与commitSync()方法相反,异步提交的方式(commitAsync())在执行的时候消费者线程不会被阻塞,可能在提交消费位移的结果还未返回之前就开始了新一次的拉取操作。异步提交可以使消费者的性能得到一定的增强。commitAsync方法有三个不同的重载方法,具体定义如下:
public void commitAsync()
public void commitAsync(OffsetCommitCallback callback)
public void commitAsync(final Map<TopicPartition, OffsetAndMetadata> offsets,
OffsetCommitCallback callback)
关键的是这里的第二个方法和第三个方法中的callback参数,它提供了一个异步提交的回调方法,当位移提交完成后会回调OffsetCommitCallback中的onComplete()方法。这里采用第二个方法来演示回调函数的用法,关键代码如下:
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
//do some logical processing.
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets,
Exception exception) {
if (exception == null) {
System.out.println(offsets);
}else {
log.error("fail to commit offsets {}", offsets, exception);
}
}
});
}
commitAsync()提交的时候同样会有失败的情况发生,那么我们应该怎么处理呢?读者有可能想到的是重试,问题的关键也就在这里了。如果某一次异步提交的消费位移为x,但是提交失败了,然后下一次又异步提交了消费位移为x+y,这次成功了。如果这里引入了重试机制,前一次的异步提交的消费位移在重试的时候提交成功了,那么此时的消费位移又变为了x。如果此时发生异常(或者再均衡),那么恢复之后的消费者(或者新的消费者)就会从x处开始消费消息,这样就发生了重复消费的问题。
为此我们可以设置一个递增的序号来维护异步提交的顺序,每次位移提交之后就增加序号相对应的值。在遇到位移提交失败需要重试的时候,可以检查所提交的位移和序号的值的大小,如果前者小于后者,则说明有更大的位移已经提交了,不需要再进行本次重试;如果两者相同,则说明可以进行重试提交。除非程序编码错误,否则不会出现前者大于后者的情况。
如果位移提交失败的情况经常发生,那么说明系统肯定出现了故障,在一般情况下,位移提交失败的情况很少发生,不重试也没有关系,后面的提交也会有成功的。重试会增加代码逻辑的复杂度,不重试会增加重复消费的概率。如果消费者异常退出,那么这个重复消费的问题就很难避免,因为这种情况下无法及时提交消费位移;如果消费者正常退出或发生再均衡的情况,那么可以在退出或再均衡执行之前使用同步提交的方式做最后的把关。
控制或关闭消费
KafkaConsumer提供了对消费速度进行控制的方法,在有些应用场景下我们可能需要暂停某些分区的消费而先消费其他分区,当达到一定条件时再恢复这些分区的消费。KafkaConsumer中使用pause()和resume()方法来分别实现暂停某些分区在拉取操作时返回数据给客户端和恢复某些分区向客户端返回数据的操作。这两个方法的具体定义如下:
public void pause(Collection<TopicPartition> partitions)
public void resume(Collection<TopicPartition> partitions)
之前的示例展示的都是使用一个while循环来包裹住poll()方法及相应的消费逻辑,如何优雅地退出这个循环也很有考究。细心的读者可能注意到有些示例代码并不是以while(true)的形式做简单的包裹,而是使用while(isRunning.get())的方式,这样可以通过在其他地方设定isRunning.set(false)来退出while循环。还有一种方式是调用KafkaConsumer的wakeup()方法,wakeup()方法是KafkaConsumer中唯一可以从其他线程里安全调用的方法(KafkaConsumer是非线程安全的),调用wakeup()方法后可以退出poll()的逻辑,并抛出WakeupException的异常,我们也不需要处理WakeupException的异常,它只是一种跳出循环的方式。
跳出循环以后一定要显式地执行关闭动作以释放运行过程中占用的各种系统资源,包括内存资源、Socket连接等。KafkaConsumer提供了close()方法来实现关闭.
指定偏移量,消息回溯
public void seek(TopicPartition partition, long offset)
seek()方法中的参数partition表示分区,而offset参数用来指定从分区的哪个位置开始消费。seek()方法只能重置消费者分配到的分区的消费位置,而分区的分配是在poll()方法的调用过程中实现的。也就是说,在执行seek()方法之前需要先执行一次poll()方法,等到分配到分区之后才可以重置消费位置。seek()方法的使用示例如代码清单35所示
//代码清单12-1 seek方法的使用示例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
consumer.poll(Duration.ofMillis(10000)); ①
Set<TopicPartition> assignment = consumer.assignment(); ②
for (TopicPartition tp : assignment) {
consumer.seek(tp, 10); ③
}
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
//consume the record.
}
上面示例中第③行设置了每个分区的消费位置为10。第②行中的assignment()方法是用来获取消费者所分配到的分区信息的,这个方法的具体定义如下:
public Set<TopicPartition> assignment()
如果我们将代码清单35中第①行poll()方法的参数设置为0,即这一行替换为:
consumer.poll(Duration.ofMillis(0));
在此之后,会发现seek()方法并未有任何作用。因为当poll()方法中的参数为0时,此方法立刻返回,那么poll()方法内部进行分区分配的逻辑就会来不及实施。也就是说,消费者此时并未分配到任何分区,如此第②行中的assignment便是一个空列表,第③行代码也不会执行。那么这里的timeout参数设置为多少合适呢?太短会使分配分区的动作失败,太长又有可能造成一些不必要的等待。我们可以通过KafkaConsumer的assignment()方法来判定是否分配到了相应的分区:
//代码清单12-2 seek()方法的另一种使用示例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {//如果不为0,则说明已经成功分配到了分区
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}
for (TopicPartition tp : assignment) {
consumer.seek(tp, 10);
}
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
//consume the record.
}
如果对未分配到的分区执行seek()方法,那么会报出IllegalStateException的异常。
有时候我们并不知道特定的消费位置,却知道一个相关的时间点,比如我们想要消费昨天8点之后的消息,这个需求更符合正常的思维逻辑。此时我们无法直接使用seek()方法来追溯到相应的位置。KafkaConsumer同样考虑到了这种情况,它提供了一个offsetsForTimes()方法,通过timestamp来查询与此对应的分区位置。
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(
Map<TopicPartition, Long> timestampsToSearch)
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(
Map<TopicPartition, Long> timestampsToSearch,
Duration timeout)
offsetsForTimes()方法的参数timestampsToSearch是一个Map类型,key为待查询的分区,而value为待查询的时间戳,该方法会返回时间戳大于等于待查询时间的第一条消息对应的位置和时间戳,对应于OffsetAndTimestamp中的offset和timestamp字段。
下面的示例演示了offsetsForTimes()和seek()之间的使用方法,首先通过offsetForTimes()方法获取一天之前的消息位置,然后使用seek()方法追溯到相应位置开始消费
Map<TopicPartition, Long> timestampToSearch = new HashMap<>();
for (TopicPartition tp : assignment) {
timestampToSearch.put(tp, System.currentTimeMillis()-1*24*3600*1000);
}
Map<TopicPartition, OffsetAndTimestamp> offsets =
consumer.offsetsForTimes(timestampToSearch);
for (TopicPartition tp : assignment) {
OffsetAndTimestamp offsetAndTimestamp = offsets.get(tp);
if (offsetAndTimestamp != null) {
consumer.seek(tp, offsetAndTimestamp.offset());
}
}
Kafka中的消费位移是存储在一个内部主题中的,而本节的seek()方法可以突破这一限制::消费位移可以保存在任意的存储介质中,例如数据库、文件系统等。以数据库为例,我们将消费位移保存在其中的一个表中,在下次消费的时候可以读取存储在数据表中的消费位移并通过seek()方法指向这个具体的位置
consumer.seek(tp, offsets.get(tp)+1);
seek()方法为我们提供了从特定位置读取消息的能力,我们可以通过这个方法来向前跳过若干消息,也可以通过这个方法来向后回溯若干消息,这样为消息的消费提供了很大的灵活性。seek()方法也为我们提供了将消费位移保存在外部存储介质中的能力,还可以配合再均衡监听器来提供更加精准的消费能力。
再均衡
再均衡是指分区的所属权从一个消费者转移到另一消费者的行为,它为消费组具备高可用性和伸缩性提供保障,使我们可以既方便又安全地删除消费组内的消费者或往消费组内添加消费者。不过在再均衡发生期间,消费组内的消费者是无法读取消息的。也就是说,在再均衡发生期间的这一小段时间内,消费组会变得不可用。另外,当一个分区被重新分配给另一个消费者时,消费者当前的状态也会丢失。比如消费者消费完某个分区中的一部分消息时还没有来得及提交消费位移就发生了再均衡操作,之后这个分区又被分配给了消费组内的另一个消费者,原来被消费完的那部分消息又被重新消费一遍,也就是发生了重复消费。一般情况下,应尽量避免不必要的再均衡的发生。
将全部消费组分成多个子集,每个消费组的子集在服务端对应一个GroupCoordinator对其进行管理,GroupCoordinator是Kafka服务端中用于管理消费组的组件。而消费者客户端中的ConsumerCoordinator组件负责与GroupCoordinator进行交互。
ConsumerCoordinator与GroupCoordinator之间最重要的职责就是负责执行消费者再均衡的操作,包括前面提及的分区分配的工作也是在再均衡期间完成的。就目前而言,一共有如下几种情形会触发再均衡的操作:
- 有新的消费者加入消费组。
- 有消费者宕机下线。消费者并不一定需要真正下线,例如遇到长时间的GC、网络延迟导致消费者长时间未向GroupCoordinator发送心跳等情况时,GroupCoordinator会认为消费者已经下线。
- 有消费者主动退出消费组(发送LeaveGroupRequest请求)。比如客户端调用了unsubscrible()方法取消对某些主题的订阅。
- 消费组所对应的GroupCoorinator节点发生了变更。·消费组内所订阅的任一主题或者主题的分区数量发生变化。
下面就以一个简单的例子来讲解一下再均衡操作的具体内容。当有消费者加入消费组时,消费者、消费组及组协调器之间会经历一下几个阶段。
- FIND_COORDINATOR
- JOIN_GROUP
- 选举消费组的leader
- 选举分区分配策略
- SYNC_GROUP
- HEARTBEAT
多线程实现
KafkaProducer是线程安全的,然而KafkaConsumer却是非线程安全的。KafkaConsumer中定义了一个acquire()方法,用来检测当前是否只有一个线程在操作,若有其他线程正在操作则会抛出ConcurrentModifcationException异常
KafkaConsumer中的每个公用方法在执行所要执行的动作之前都会调用这个acquire()方法,只有wakeup()方法是个例外。acquire()方法的具体定义如下:
private final AtomicLong currentThread
= new AtomicLong(NO_CURRENT_THREAD); //KafkaConsumer中的成员变量
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() &&
!currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException
("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
acquire()方法和我们通常所说的锁(synchronized、Lock等)不同,它不会造成阻塞等待,我们可以将其看作一个轻量级锁,它仅通过线程操作计数标记的方式来检测线程是否发生了并发操作,以此保证只有一个线程在操作。acquire()方法和release()方法成对出现,表示相应的加锁和解锁操作。release()方法也很简单,具体定义如下:
private void release() {
if (refcount.decrementAndGet() == 0)
currentThread.set(NO_CURRENT_THREAD);
}
acquire()方法和release()方法都是私有方法,因此在实际应用中不需要我们显式地调用,但了解其内部的机理之后可以促使我们正确、有效地编写相应的程序逻辑。
KafkaConsumer非线程安全并不意味着我们在消费消息的时候只能以单线程的方式执行。如果生产者发送消息的速度大于消费者处理消息的速度,那么就会有越来越多的消息得不到及时的消费,造成了一定的延迟。除此之外,由于Kafka中消息保留机制的作用,有些消息有可能在被消费之前就被清理了,从而造成消息的丢失。我们可以通过多线程的方式来实现消息消费,多线程的目的就是为了提高整体的消费能力。多线程的实现方式有多种,第一种也是最常见的方式:线程封闭,即为每个线程实例化一个KafkaConsumer对象,如图310所示。
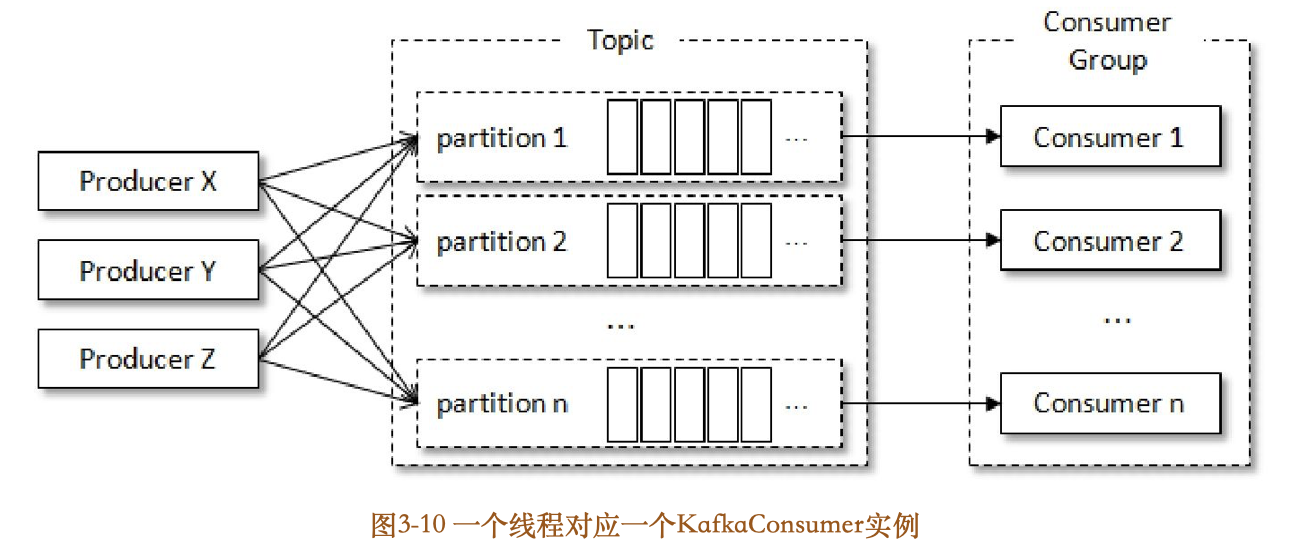
一个线程对应一个KafkaConsumer实例,我们可以称之为消费线程。一个消费线程可以消费一个或多个分区中的消息,所有的消费线程都隶属于同一个消费组。这种实现方式的并发度受限于分区的实际个数,根据3.1节中介绍的消费者与分区数的关系,当消费线程的个数大于分区数时,就有部分消费线程一直处于空闲的状态。
与此对应的第二种方式是多个消费线程同时消费同一个分区,这个通过assign()、seek()等方法实现,这样可以打破原有的消费线程的个数不能超过分区数的限制,进一步提高了消费的能力。不过这种实现方式对于位移提交和顺序控制的处理就会变得非常复杂,实际应用中使用得极少,笔者也并不推荐。
如果对消息的处理非常迅速,那么poll()拉取的频次也会更高,进而整体消费的性能也会提升;相反,如果在这里对消息的处理缓慢,比如进行一个事务性操作,或者等待一个RPC的同步响应,那么poll()拉取的频次也会随之下降,进而造成整体消费性能的下降。一般而言,poll()拉取消息的速度是相当快的,而整体消费的瓶颈也正是在处理消息这一块,如果我们通过一定的方式来改进这一部分,那么我们就能带动整体消费性能的提升。参考图311,考虑第三种实现方式,将处理消息模块改成多线程的实现方式
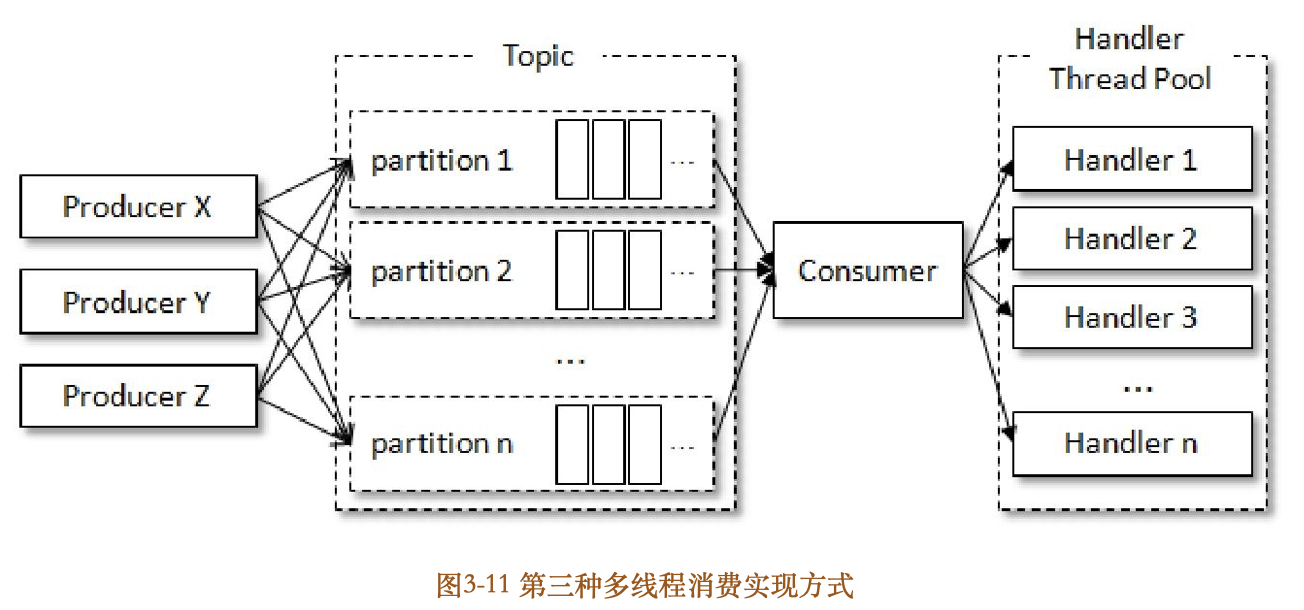
//代码清单14-2 第三种多线程消费实现方式
public class ThirdMultiConsumerThreadDemo {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
//省略initConfig()方法,具体请参考代码清单14-1
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumerThread consumerThread =
new KafkaConsumerThread(props, topic,
Runtime.getRuntime().availableProcessors());
consumerThread.start();
}
public static class KafkaConsumerThread extends Thread {
private KafkaConsumer<String, String> kafkaConsumer;
private ExecutorService executorService;
private int threadNumber;
public KafkaConsumerThread(Properties props,
String topic, int threadNumber) {
kafkaConsumer = new KafkaConsumer<>(props);
kafkaConsumer.subscribe(Collections.singletonList(topic));
this.threadNumber = threadNumber;
executorService = new ThreadPoolExecutor(threadNumber, threadNumber,
0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records =
kafkaConsumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
executorService.submit(new RecordsHandler(records));
} ①
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
public static class RecordsHandler extends Thread{
public final ConsumerRecords<String, String> records;
public RecordsHandler(ConsumerRecords<String, String> records) {
this.records = records;
}
@Override
public void run(){
//处理records.
}
}
}
第三种实现方式相比第一种实现方式而言,除了横向扩展的能力,还可以减少TCP连接对系统资源的消耗,不过缺点就是对于消息的顺序处理就比较困难了。这里引入一个共享变量offsets来参与提交,如图312所示。
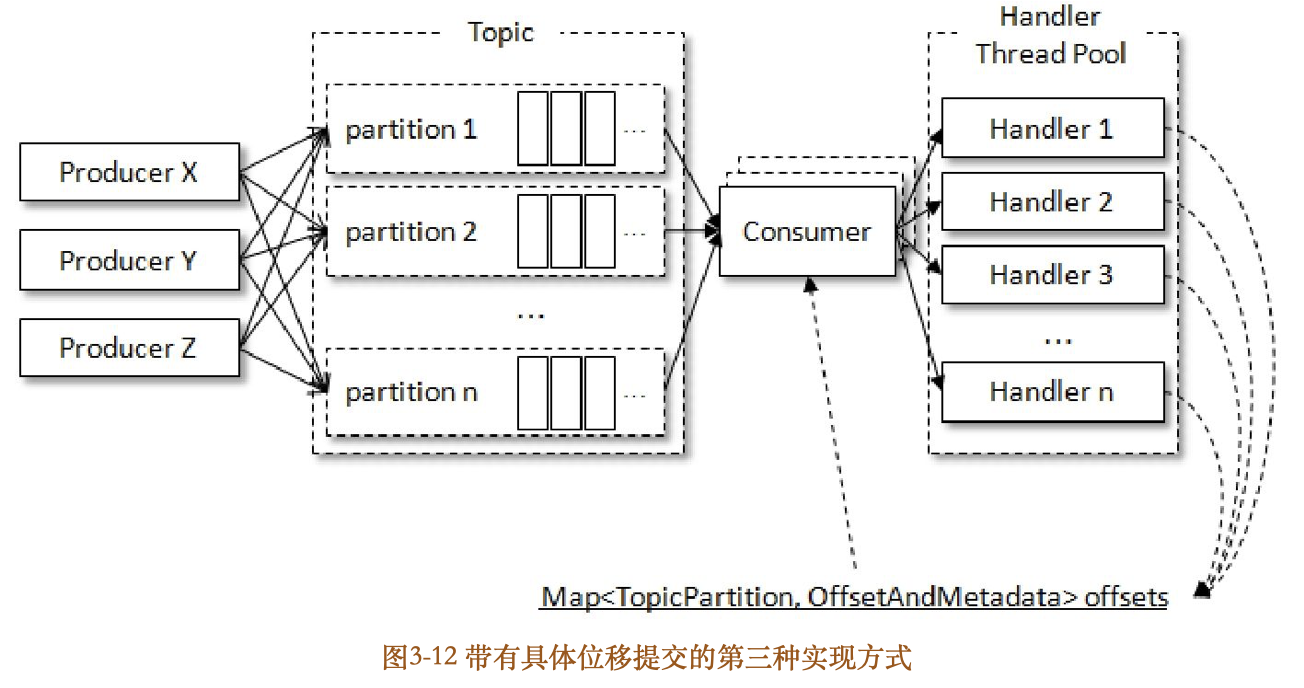
每一个处理消息的RecordHandler类在处理完消息之后都将对应的消费位移保存到共享变量offsets中,KafkaConsumerThread在每一次poll()方法之后都读取offsets中的内容并对其进行位移提交。注意在实现的过程中对offsets读写需要加锁处理,防止出现并发问题。并且在写入offsets的时候需要注意位移覆盖的问题
读者可以细想一下这样实现是否万无一失?其实这种位移提交的方式会有数据丢失的风险。对于同一个分区中的消息,假设一个处理线程RecordHandler1正在处理offset为0~99的消息,而另一个处理线程RecordHandler2已经处理完了offset为100~199的消息并进行了位移提交,此时如果RecordHandler1发生异常,则之后的消费只能从200开始而无法再次消费0~99的消息,从而造成了消息丢失的现象。这里虽然针对位移覆盖做了一定的处理,但还没有解决异常情况下的位移覆盖问题。对此就要引入更加复杂的处理机制,这里再提供一种解决思路,参考图313,总体结构上是基于滑动窗口实现的。对于第三种实现方式而言,它所呈现的结构是通过消费者拉取分批次的消息,然后提交给多线程进行处理,而这里的滑动窗口式的实现方式是将拉取到的消息暂存起来,多个消费线程可以拉取暂存的消息,这个用于暂存消息的缓存大小即为滑动窗口的大小,总体上而言没有太多的变化,不同的是对于消费位移的把控
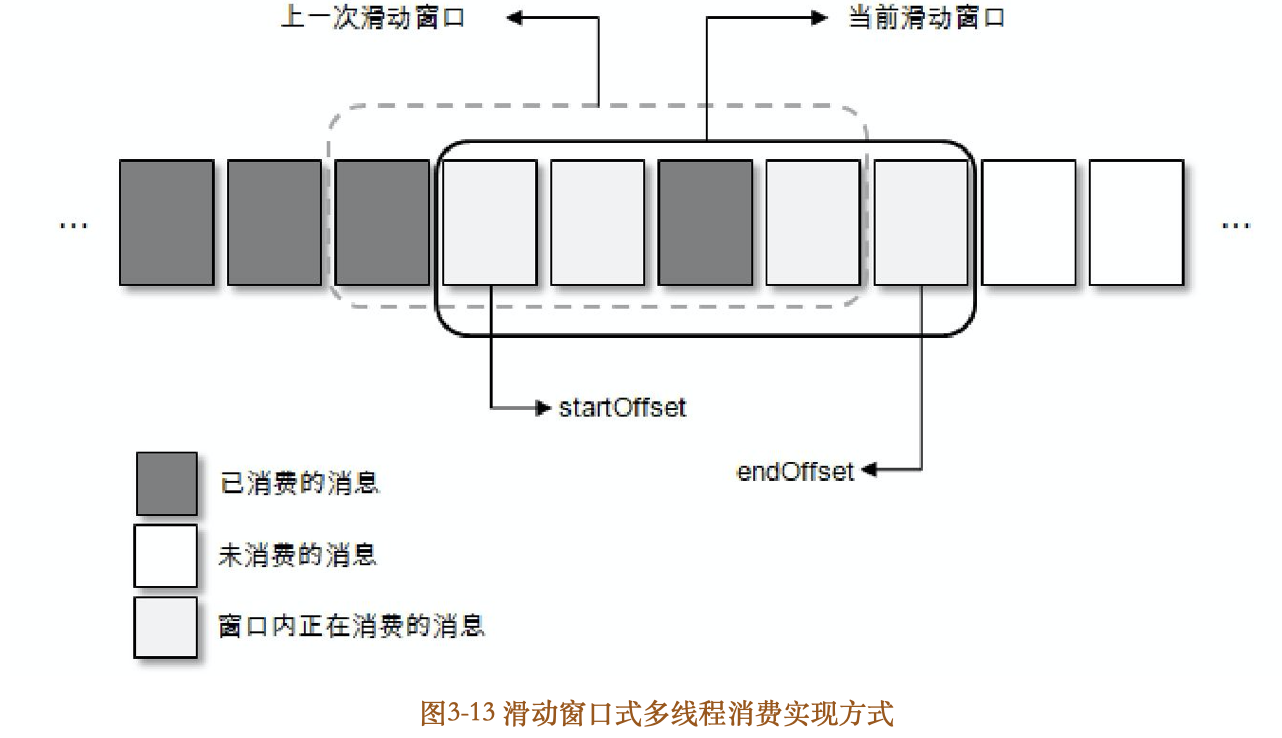
如图313所示,每一个方格代表一个批次的消息,一个滑动窗口包含若干方格,startOffset标注的是当前滑动窗口的起始位置,endOffset标注的是末尾位置。每当startOffset指向的方格中的消息被消费完成,就可以提交这部分的位移,与此同时,窗口向前滑动一格,删除原来startOffset所指方格中对应的消息,并且拉取新的消息进入窗口。滑动窗口的大小固定,所对应的用来暂存消息的缓存大小也就固定了,这部分内存开销可控。方格大小和滑动窗口的大小同时决定了消费线程的并发数:一个方格对应一个消费线程,对于窗口大小固定的情况,方格越小并行度越高;对于方格大小固定的情况,窗口越大并行度越高。不过,若窗口设置得过大,不仅会增大内存的开销,而且在发生异常(比如Crash)的情况下也会引起大量的重复消费,同时还考虑线程切换的开销,建议根据实际情况设置一个合理的值,不管是对于方格还是窗口而言,过大或过小都不合适。
如果一个方格内的消息无法被标记为消费完成,那么就会造成startOffset的悬停。为了使窗口能够继续向前滑动,那么就需要设定一个阈值,当startOffset悬停一定的时间后就对这部分消息进行本地重试消费,如果重试失败就转入重试队列,如果还不奏效就转入死信队列。真实应用中无法消费的情况极少,一般是由业务代码的处理逻辑引起的,比如消息中的内容格式与业务处理的内容格式不符,无法对这条消息进行决断,这种情况可以通过优化代码逻辑或采取丢弃策略来避免。如果需要消息高度可靠,也可以将无法进行业务逻辑的消息(这类消息可以称为死信)存入磁盘、数据库或Kafka,然后继续消费下一条消息以保证整体消费进度合理推进,之后可以通过一个额外的处理任务来分析死信进而找出异常的原因。
事务与幂等
一般而言,消息中间件的消息传输保障有3个层级,分别如下。
- at most once:至多一次。消息可能会丢失,但绝对不会重复传输。
- at least once:最少一次。消息绝不会丢失,但可能会重复传输。
- exactly once:恰好一次。每条消息肯定会被传输一次且仅传输一次。
Kafka的消息传输保障机制非常直观。当生产者向Kafka发送消息时,一旦消息被成功提交到日志文件,由于多副本机制的存在,这条消息就不会丢失。如果生产者发送消息到Kafka之后,遇到了网络问题而造成通信中断,那么生产者就无法判断该消息是否已经提交。虽然Kafka无法确定网络故障期间发生了什么,但生产者可以进行多次重试来确保消息已经写入Kafka,这个重试的过程中有可能会造成消息的重复写入,所以这里Kafka提供的消息传输保障为at least once。
对消费者而言,消费者处理消息和提交消费位移的顺序在很大程度上决定了消费者提供哪一种消息传输保障。如果消费者在拉取完消息之后,应用逻辑先处理消息后提交消费位移,那么在消息处理之后且在位移提交之前消费者宕机了,待它重新上线之后,会从上一次位移提交的位置拉取,这样就出现了重复消费,因为有部分消息已经处理过了只是还没来得及提交消费位移,此时就对应at least once。如果消费者在拉完消息之后,应用逻辑先提交消费位移后进行消息处理,那么在位移提交之后且在消息处理完成之前消费者宕机了,待它重新上线之后,会从已经提交的位移处开始重新消费,但之前尚有部分消息未进行消费,如此就会发生消息丢失,此时就对应at most once。
Kafka从0.11.0.0版本开始引入了幂等和事务这两个特性,以此来实现EOS(exactly once semantics,精确一次处理语义)。
幂等
所谓的幂等,简单地说就是对接口的多次调用所产生的结果和调用一次是一致的。生产者在进行重试的时候有可能会重复写入消息,而使用Kafka的幂等性功能之后就可以避免这种情况。
开启幂等性功能的方式很简单,只需要显式地将生产者客户端参数enable.idempotence设置为true即可(这个参数的默认值为false)
为了实现生产者的幂等性,Kafka为此引入了producer id(以下简称PID)和序列号(sequence number)这两个概念。每个新的生产者实例在初始化的时候都会被分配一个PID,这个PID对用户而言是完全透明的。对于每个PID,消息发送到的每一个分区都有对应的序列号,这些序列号从0开始单调递增。生产者每发送一条消息就会将<PID,分区>对应的序列号的值加1。
broker端会在内存中为每一对<PID,分区>维护一个序列号。对于收到的每一条消息,只有当它的序列号的值(SN_new)比broker端中维护的对应的序列号的值(SN_old)大1(即SN_new=SN_old+1)时,broker才会接收它。如果SN_new<SN_old+1,那么说明消息被重复写入,broker可以直接将其丢弃。如果SN_new>SN_old+1,那么说明中间有数据尚未写入,出现了乱序,暗示可能有消息丢失,对应的生产者会抛出OutOfOrderSequenceException,这个异常是一个严重的异常,后续的诸如send()、beginTransaction()、commitTransaction()等方法的调用都会抛出IllegalStateException的异常。
引入序列号来实现幂等也只是针对每一对<PID,分区>而言的,也就是说,Kafka的幂等只能保证单个生产者会话(session)中单分区的幂等。
ProducerRecord<String, String> record
= new ProducerRecord<>(topic, "key", "msg");
producer.send(record);
producer.send(record);
注意,上面示例中发送了两条相同的消息,不过这仅仅是指消息内容相同,但对Kafka而言是两条不同的消息,因为会为这两条消息分配不同的序列号。Kafka并不会保证消息内容的幂等。
事务
幂等性并不能跨多个分区运作,而事务可以弥补这个缺陷。事务可以保证对多个分区写入操作的原子性。操作的原子性是指多个操作要么全部成功,要么全部失败,不存在部分成功、部分失败的可能。
Kafka中的事务可以使应用程序将消费消息、生产消息、提交消费位移当作原子操作来处理,同时成功或失败,即使该生产或消费会跨多个分区。
为了实现事务,应用程序必须提供唯一的transactional Id,这个transactional Id通过客户端参数transactional.id来显式设置
事务要求生产者开启幂等特性,因此通过将transactional.id参数设置为非空从而开启事务特性的同时需要将enable.idempotence设置为true(如果未显式设置,则KafkaProducer默认会将它的值设置为true),如果用户显式地将enable.idempotence设置为false,则会报出ConfigException:
transactional Id与PID一一对应,两者之间所不同的是transactional Id由用户显式设置,而PID是由Kafka内部分配的。另外,为了保证新的生产者启动后具有相同transactional Id的旧生产者能够立即失效,每个生产者通过transactional Id获取PID的同时,还会获取一个单调递增的producer epoch(对应下面要讲述的KafkaProducer.initTransactions()方法)。
生产者
从生产者的角度分析,通过事务,Kafka可以保证跨生产者会话的消息幂等发送,以及跨生产者会话的事务恢复。前者表示具有相同transactional Id的新生产者实例被创建且工作的时候,旧的且拥有相同transactional Id的生产者实例将不再工作。后者指当某个生产者实例宕机后,新的生产者实例可以保证任何未完成的旧事务要么被提交(Commit),要么被中止(Abort),如此可以使新的生产者实例从一个正常的状态开始工作。
KafkaProducer提供了5个与事务相关的方法,详细如下:
void initTransactions();
void beginTransaction() throws ProducerFencedException;
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId)
throws ProducerFencedException;
void commitTransaction() throws ProducerFencedException;
void abortTransaction() throws ProducerFencedException;
initTransactions()方法用来初始化事务,这个方法能够执行的前提是配置了transactionalId,如果没有则会报出IllegalStateException
beginTransaction()方法用来开启事务;sendOffsetsToTransaction()方法为消费者提供在事务内的位移提交的操作;commitTransaction()方法用来提交事务;abortTransaction()方法用来中止事务,类似于事务回滚。
代码清单14-1 事务消息发送示例
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId);
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
producer.initTransactions();
producer.beginTransaction();
try {
//处理业务逻辑并创建ProducerRecord
ProducerRecord<String, String> record1 = new ProducerRecord<>(topic, "msg1");
producer.send(record1);
ProducerRecord<String, String> record2 = new ProducerRecord<>(topic, "msg2");
producer.send(record2);
ProducerRecord<String, String> record3 = new ProducerRecord<>(topic, "msg3");
producer.send(record3);
//处理一些其他逻辑
producer.commitTransaction();
} catch (ProducerFencedException e) {
producer.abortTransaction();
}
producer.close();
消费者
而从消费者的角度分析,事务能保证的语义相对偏弱。出于以下原因,Kafka并不能保证已提交的事务中的所有消息都能够被消费:
- 对采用日志压缩策略的主题而言,事务中的某些消息有可能被清理(相同key的消息,后写入的消息会覆盖前面写入的消息)。
- 事务中消息可能分布在同一个分区的多个日志分段(LogSegment)中,当老的日志分段被删除时,对应的消息可能会丢失。
- 消费者可以通过seek()方法访问任意offset的消息,从而可能遗漏事务中的部分消息。
- 消费者在消费时可能没有分配到事务内的所有分区,如此它也就不能读取事务中的所有消息。
在消费端有一个参数isolation.level,与事务有着莫大的关联,这个参数的默认值为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。
实现
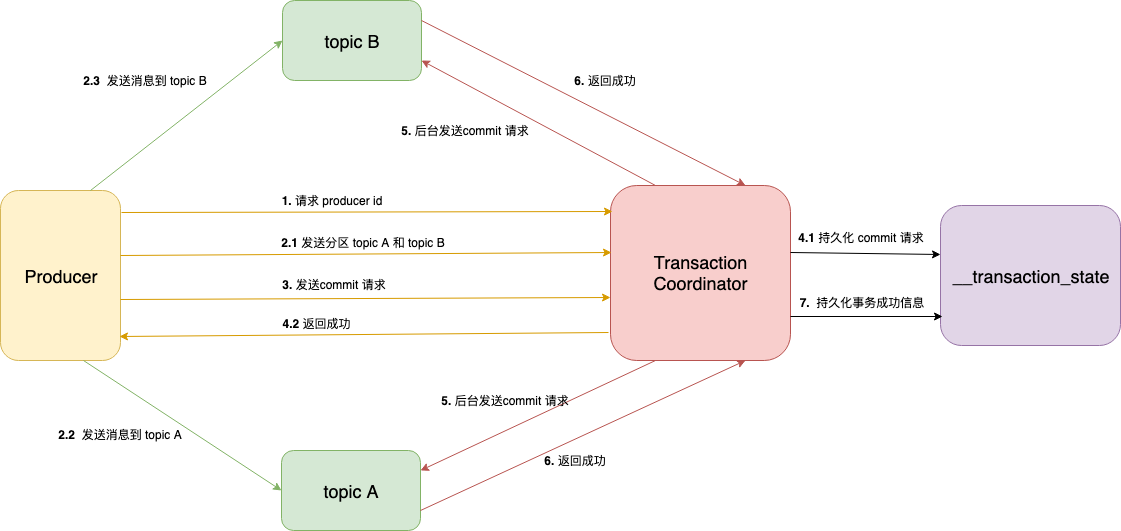
每一个生产者都会被指派一个特定的TransactionCoordinator,所有的事务逻辑包括分派PID等都是由TransactionCoordinator来负责实施的。TransactionCoordinator会将事务状态持久化到内部主题__transaction_state中。
主题与分区
分区管理
优先副本的选举
分区使用多副本机制来提升可靠性,但只有leader副本对外提供读写服务,而follower副本只负责在内部进行消息的同步。如果一个分区的leader副本不可用,那么就意味着整个分区变得不可用,此时就需要Kafka从剩余的follower副本中挑选一个新的leader副本来继续对外提供服务。虽然不够严谨,但从某种程度上说,broker节点中leader副本个数的多少决定了这个节点负载的高低。
在创建主题的时候,该主题的分区及副本会尽可能均匀地分布到Kafka集群的各个broker节点上,对应的leader副本的分配也比较均匀。针对同一个分区而言,同一个broker节点中不可能出现它的多个副本,即Kafka集群的一个broker中最多只能有它的一个副本,我们可以将leader副本所在的broker节点叫作分区的leader节点,而follower副本所在的broker节点叫作分区的follower节点。
随着时间的更替,Kafka集群的broker节点不可避免地会遇到宕机或崩溃的问题,当分区的leader节点发生故障时,其中一个follower节点就会成为新的leader节点,这样就会导致集群的负载不均衡,从而影响整体的健壮性和稳定性。当原来的leader节点恢复之后重新加入集群时,它只能成为一个新的follower节点而不再对外提供服务。
为了能够有效地治理负载失衡的情况,Kafka引入了优先副本(preferredreplica)的概念。
所谓的优先副本是指在AR集合列表中的第一个副本。理想情况下,优先副本就是该分区的leader副本,所以也可以称之为preferredleader。Kafka要确保所有主题的优先副本在Kafka集群中均匀分布,这样就保证了所有分区的leader均衡分布。如果leader分布过于集中,就会造成集群负载不均衡。
所谓的优先副本的选举是指通过一定的方式促使优先副本选举为leader副本,以此来促进集群的负载均衡,这一行为也可以称为“分区平衡”。
在Kafka中可以提供分区自动平衡的功能,与此对应的broker端参数是auto.leader.rebalance.enable,此参数的默认值为true,即默认情况下此功能是开启的。如果开启分区自动平衡的功能,则Kafka的控制器会启动一个定时任务,这个定时任务会轮询所有的broker节点,计算每个broker节点的分区不平衡率(broker中的不平衡率=非优先副本的leader个数/分区总数)是否超过leader.imbalance.per.broker.percentage参数配置的比值,默认值为10%,如果超过设定的比值则会自动执行优先副本的选举动作以求分区平衡。执行周期由参数leader.imbalance.check.interval.seconds控制,默认值为300秒,即5分钟。
不过在生产环境中不建议将auto.leader.rebalance.enable设置为默认的true,因为这可能引起负面的性能问题,也有可能引起客户端一定时间的阻塞。因为执行的时间无法自主掌控,如果在关键时期(比如电商大促波峰期)执行关键任务的关卡上执行优先副本的自动选举操作,势必会有业务阻塞、频繁超时之类的风险。
分区重分配
当集群中的一个节点突然宕机下线时,如果节点上的分区是单副本的,那么这些分区就变得不可用了,在节点恢复前,相应的数据也就处于丢失状态;如果节点上的分区是多副本的,那么位于这个节点上的leader副本的角色会转交到集群的其他follower副本中。总而言之,这个节点上的分区副本都已经处于功能失效的状态,Kafka并不会将这些失效的分区副本自动地迁移到集群中剩余的可用broker节点上,如果放任不管,则不仅会影响整个集群的均衡负载,还会影响整体服务的可用性和可靠性。
当要对集群中的一个节点进行有计划的下线操作时,为了保证分区及副本的合理分配,我们也希望通过某种方式能够将该节点上的分区副本迁移到其他的可用节点上。
当集群中新增broker节点时,只有新创建的主题分区才有可能被分配到这个节点上,而之前的主题分区并不会自动分配到新加入的节点中,因为在它们被创建时还没有这个新节点,这样新节点的负载和原先节点的负载之间严重不均衡。
为了解决上述问题,需要让分区副本再次进行合理的分配,也就是所谓的分区重分配。kafka提供脚本执行分区重分配。
选择合适的分区数
一般情况下,根据预估的吞吐量及是否与key相关的规则来设定分区数即可,后期可以通过增加分区数、增加broker或分区重分配等手段来进行改进。如果一定要给一个准则,则建议将分区数设定为集群中broker的倍数,即假定集群中有3个broker节点,可以设定分区数为3、6、9等,至于倍数的选定可以参考预估的吞吐量。不过,如果集群中的broker节点数有很多,比如大几十或上百、上千,那么这种准则也不太适用,在选定分区数时进一步可以引入基架等参考因素。