mysql之高可用

参考 http://mysql.taobao.org/monthly/2018/12/04/ https://zhuanlan.zhihu.com/p/25960208 https://zhangjunjia.github.io/2019/03/16/mysql-mmm-mha/
故障恢复
MySQL的事务处理—两阶段事务提交2PC
MySQL数据库的INNODB是一款支持OLTP的存储引擎,为支持MySQL的高可用,支持跨机搭建高可用数据库集群。
MySQL采用了一种简单有效的机制 ———— 基于binlog的复制。
binlog是binary log的简称,实际上它是一种逻辑日志,相对InnoDB引擎的物理日志,它的数据量更小,格式也更简单,更易于跨机复制,尤其是对于网络环境不是很好的情况下,更具有天然的优势。
那么MySQL是如何协调InnoDB引擎与Binlog日志之间的关系呢?
MySQL采用了两阶段事务提交(Two-Phase Commit Protocol)协议,当操作完成后,首先Prepare事务,在binlog中实际上只是fake一下,不作任何事情,而是innodb层需要将prepare写入redolog中;然后执行commit事务,首先在binlog文件中写入这些操作的binlog日志,完成后再在Innodb的redolog中写入commit日志。(基于事务复制)
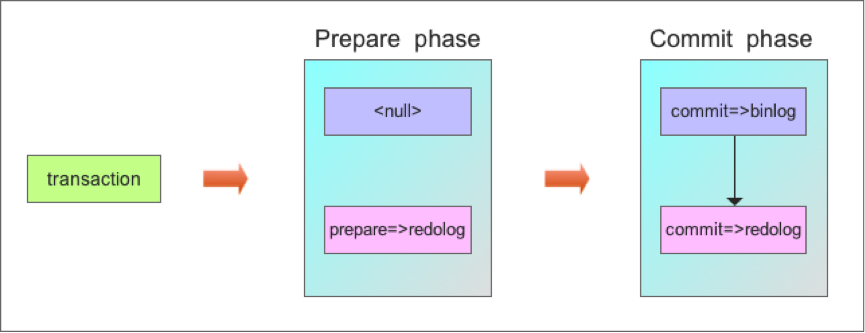
注意在写binlog日志时,有个参数sync_binlog来控制何时将binlog fsync到磁盘。
- 参数为0时,并不是立即fsync文件到磁盘,而是依赖于操作系统的fsync机制;
- 参数为1时,立即fsync文件到磁盘;
- 参数大于1时,则达到指定提交次数后,统一fsync到磁盘。 因此只有当sync_binlog参数为1时,才是最安全的,当其不为1时,都存在binlog未fsync到磁盘的风险,若此时发生断电等故障,就有可能出现此事务并未刷出到磁盘,从而故障恢复时将此事务回滚的情况。
基于binlog的事务恢复流程
了解了MySQL关于Innodb与Binlog的两阶段提交机制后,就可以更深入去探究MySQL在故障恢复时的处理过程。
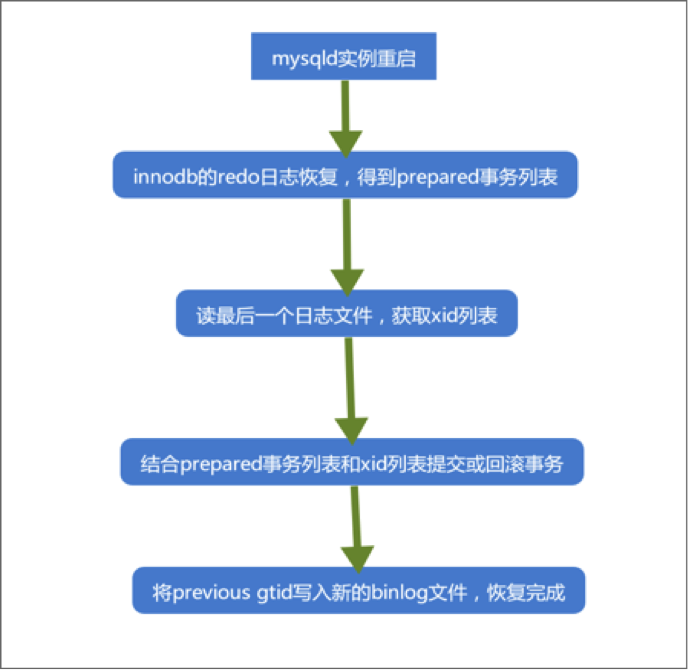
在MySQL启动时,首先会初始化存储引擎,如本例中的InnoDB引擎,然后InnoDB引擎层会读取redolog进行InnoDB层的故障恢复,回滚未prepared和commit的事务,但对于已经prepared,但未commit的事务,暂时挂起,保存到一个链表中,等待后续读取binlog日志,然后根据binlog日志再对这部分prepared的事务进行处理。
接下来,MySQL会读取最后一个binlog文件。binlog文件通常是以固定的文件名加一组连续的编号来命名的,并且将其记录到一个binlog索引文件中,因此索引文件中的最后一个binlog文件即是MySQL将要读取的最后一个binlog文件。读取这个binlog文件时,通过文件头上是否存在标记LOG_EVENT_BINLOG_IN_USE_F,通过这个标记可以知道上次MySQL是正常关闭还是异常关闭,如果是异常关闭,则会进入故障恢复过程。
进入故障恢复过程后,会依次读取最后一个binlog文件中的所有log event,并将所有已提交事务的binlog日志中记录的xid提取出来添加到hash表中,以备后续对前述InnoDB故障恢复后遗留的Prepared事务继续处理。另外此处还要定位最后一个完整事务的位置,防止在上次系统异常关闭时有部分binlog日志未刷到磁盘上,即存在写了一半的binlog事务日志,这部分写了一半binlog日志的事务在MySQL中会按事务未提交来处理,后续会将其在存储引擎层回滚。
当此文件中的内容全部读出之后,一是得到一个已提交事务的列表,另一个是最后一个完整事务的位置。 然后检查由InnoDB层得到的Prepared事务列表,若Prepared事务在从Binlog中得到的提交事务列表中,则在InnoDB层提交此事务,否则回滚此事务。
基于binlog的两阶段提交对高可用复制解决方案的影响
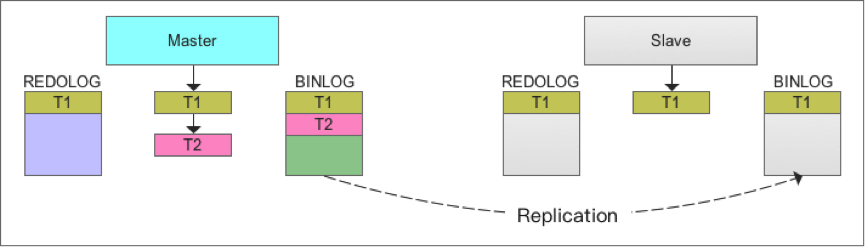
MySQL最常见的高可用解决方案就是基于binlog复制来完成的,通过将master的binlog复制到slave上,然后在slave上重放,从而达到master与slave上数据一致的效果。
正常情况下,这个方案简单、易用,基本满足大部分用户的高可用需求,但在一些特殊情况下,这个方案还是存在一些不足,可能会导致master与slave存在数据不一致的情况。 如果master与slave之间采用异步模式进行binlog复制,显然就会存在部分binlog未复制到slave的情况。
为提高可用性,MySQL支持semi-sync模式,也就是当master在提交事务之前,保证binlog已经复制到slave,并且收到slave回复的ACK后,master再将事务提交。Semi-sync模式的复制机制虽然已经极大提高了可用性,但是在极端情况下还是存在master与slave数据不一致的风险,甚至数据丢失的风险。
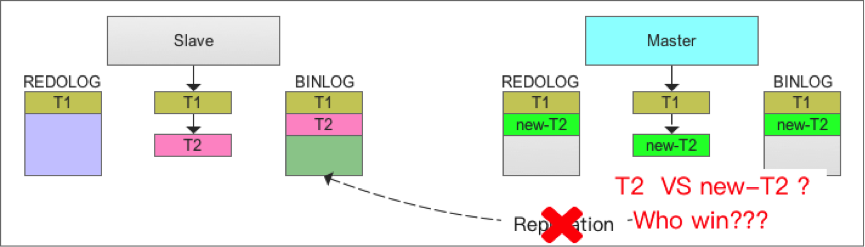
考虑一下master出现故障后无法立即恢复的情况,为保障应用的持续性,需要将slave切换为master。若在故障发生前,master恰好有事务正准备提交,并且binlog日志已经刷到磁盘,但在将binlog复制给slave过程中master故障了,备机未收到或只收到部分binlog日志,若此时slave切换为master,显然这些未收到或只收到部分binlog日志的事务是无法重现的,也就是这部分事务是丢失的。
理论上应用层并未得到事务提交的反馈,即使事务不存在也不是什么问题。问题是若此时用户查询这些事务不存在,准备重做这些事务,更糟的事情发生了,新的mater也发生故障了,并且无法立即恢复。万幸的是原来的master可以恢复工作了,直接作为master就好了,但问题出现了,用户已经在重做这些事务了,但这些事务在这个master已经存在了,原因如前述的基于binlog的事务恢复。这就好比之前买东西已经付钱给商家200块了,结果人家说没收到,我一查账户,也没少钱,那就再付一次吧,结果杯具了,付了400块给人家???
如上图所示:若T2的binlog日志尚未复制到slave时,master故障,原slave切换为master,而原master重启恢复后成为新的slave,如下图所示:
高可用必杀技–基于RAFT的多副本集群
基于RAFT协议的多副本架构,每一条数据都会被复制多份,通过多副本来增加系统的可用性,防止单副本失效而导致数据不可用。多副本之间基于RAFT协议来实现数据的一致性,只有数据存在于半数以上副本方可认为数据有效,而无效的副本数据系统会自动修复,从而确保系统只会提供一个统一的一致性视图。
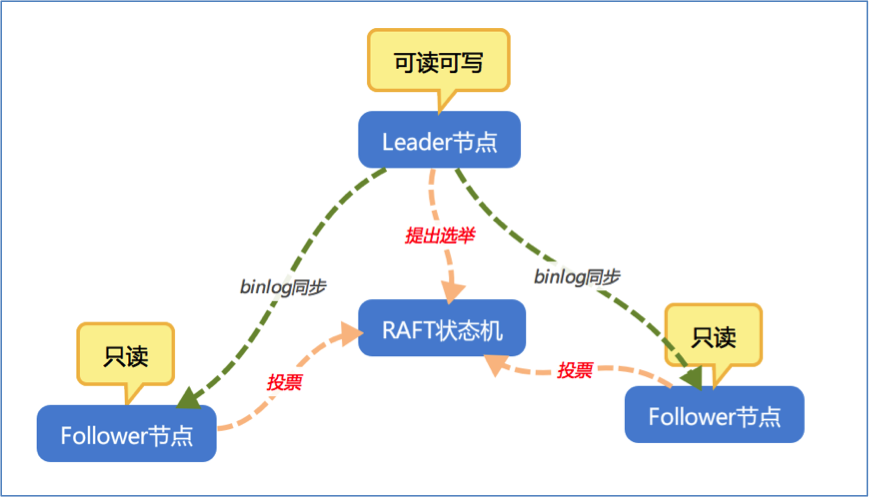
五大常见的MySQL高可用方案
主从或主主半同步复制
使用双节点数据库,搭建单向或者双向的半同步复制。在5.7以后的版本中,由于lossless replication、logical多线程复制等一些列新特性的引入,使得MySQL原生半同步复制更加可靠。
常见架构如下:
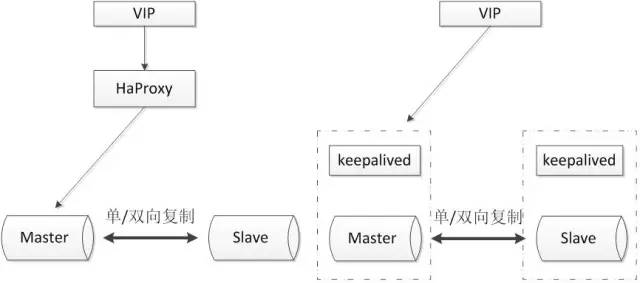
通常会和proxy、keepalived等第三方软件同时使用,即可以用来监控数据库的健康,又可以执行一系列管理命令。如果主库发生故障,切换到备库后仍然可以继续使用数据库。
优点:
- 架构比较简单,使用原生半同步复制作为数据同步的依据;
- 双节点,没有主机宕机后的选主问题,直接切换即可;
- 双节点,需求资源少,部署简单;
缺点:
- 完全依赖于半同步复制,如果半同步复制退化为异步复制,数据一致性无法得到保证;
- 需要额外考虑haproxy、keepalived的高可用机制。
半同步复制优化
半同步复制机制是可靠的。如果半同步复制一直是生效的,那么便可以认为数据是一致的。但是由于网络波动等一些客观原因,导致半同步复制发生超时而切换为异步复制,那么这时便不能保证数据的一致性。所以尽可能的保证半同步复制,便可提高数据的一致性。
该方案同样使用双节点架构,但是在原有半同复制的基础上做了功能上的优化,使半同步复制的机制变得更加可靠。
可参考的优化方案如下:
双通道复制
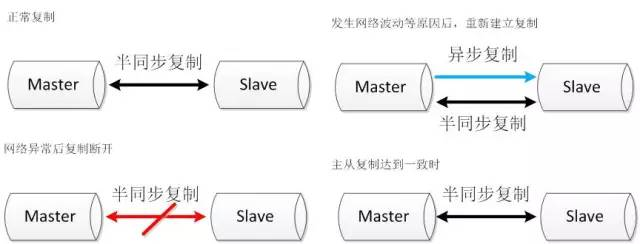
半同步复制由于发生超时后,复制断开,当再次建立起复制时,同时建立两条通道,其中一条半同步复制通道从当前位置开始复制,保证从机知道当前主机执行的进度。另外一条异步复制通道开始追补从机落后的数据。当异步复制通道追赶到半同步复制的起始位置时,恢复半同步复制。(无节点晋升,只保证恢复重连,不能重连还是丢数据)
binlog文件服务器
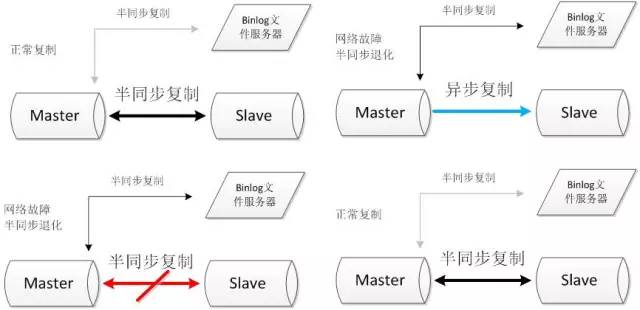
搭建两条半同步复制通道,其中连接文件服务器的半同步通道正常情况下不启用,当主从的半同步复制发生网络问题退化后,启动与文件服务器的半同步复制通道。当主从半同步复制恢复后,关闭与文件服务器的半同步复制通道。
优点:
- 双节点,需求资源少,部署简单;
- 架构简单,没有选主的问题,直接切换即可;
- 相比于原生复制,优化后的半同步复制更能保证数据的一致性。
缺点:
- 需要修改内核源码或者使用mysql通信协议。需要对源码有一定的了解,并能做一定程度的二次开发。
- 依旧依赖于半同步复制,没有从根本上解决数据一致性问题。
高可用架构优化
将双节点数据库扩展到多节点数据库,或者多节点数据库集群。可以根据自己的需要选择一主两从、一主多从或者多主多从的集群。
由于半同步复制,存在接收到一个从机的成功应答即认为半同步复制成功的特性,所以多从半同步复制的可靠性要优于单从半同步复制的可靠性。并且多节点同时宕机的几率也要小于单节点宕机的几率,所以多节点架构在一定程度上可以认为高可用性是好于双节点架构。
但是由于数据库数量较多,所以需要数据库管理软件来保证数据库的可维护性。可以选择MMM、MHA或者各个版本的proxy等等。常见方案如下:
MHA+多节点集群
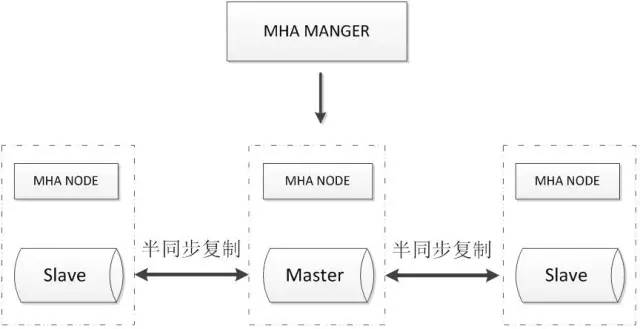
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
MHA Node运行在每台MySQL服务器上,主要作用是切换时处理二进制日志,确保切换尽量少丢数据。
MHA也可以扩展到如下的多节点集群:
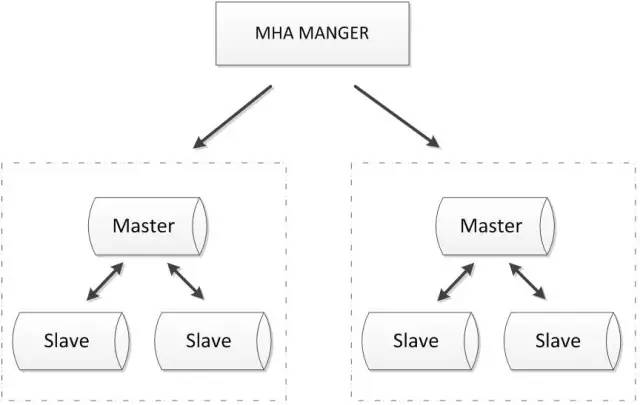
优点:
- 可以进行故障的自动检测和转移;
- 可扩展性较好,可以根据需要扩展MySQL的节点数量和结构;
- 相比于双节点的MySQL复制,三节点/多节点的MySQL发生不可用的概率更低
缺点:
- 至少需要三节点,相对于双节点需要更多的资源;
- 逻辑较为复杂,发生故障后排查问题,定位问题更加困难;
- 数据一致性仍然靠原生半同步复制保证,仍然存在数据不一致的风险;
- 可能因为网络分区发生脑裂现象
zookeeper+proxy
Zookeeper使用分布式算法保证集群数据的一致性,使用zookeeper可以有效的保证proxy的高可用性,可以较好的避免网络分区现象的产生。
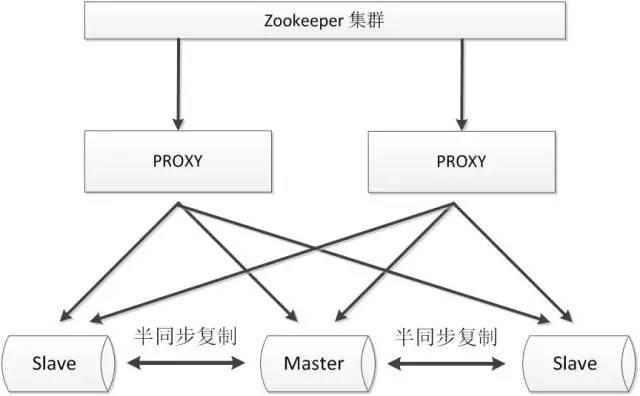
优点:
- 较好的保证了整个系统的高可用性,包括proxy、MySQL;
- 扩展性较好,可以扩展为大规模集群;
缺点:
- 数据一致性仍然依赖于原生的mysql半同步复制;
- 引入zk,整个系统的逻辑变得更加复杂;
共享存储
共享存储实现了数据库服务器和存储设备的解耦,不同数据库之间的数据同步不再依赖于MySQL的原生复制功能,而是通过磁盘数据同步的手段,来保证数据的一致性。
SAN共享储存
SAN的概念是允许存储设备和处理器(服务器)之间建立直接的高速网络(与LAN相比)连接,通过这种连接实现数据的集中式存储。常用架构如下:
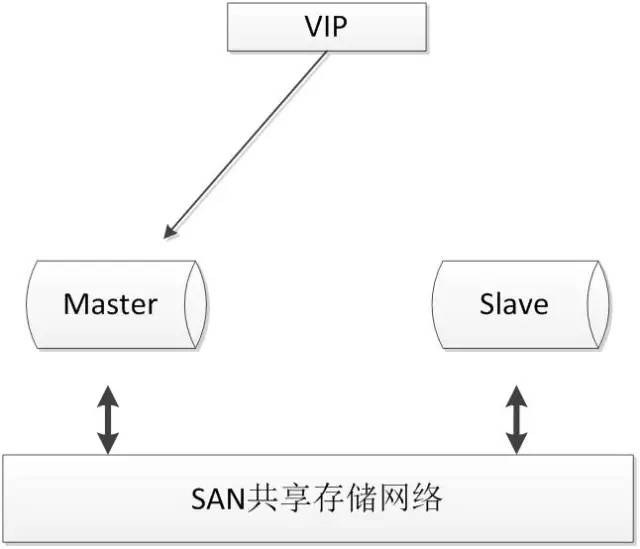
使用共享存储时,MySQL服务器能够正常挂载文件系统并操作,如果主库发生宕机,备库可以挂载相同的文件系统,保证主库和备库使用相同的数据。
优点:
- 两节点即可,部署简单,切换逻辑简单;
- 很好的保证数据的强一致性;
- 不会因为MySQL的逻辑错误发生数据不一致的情况;
缺点:
- 需要考虑共享存储的高可用;
- 价格昂贵;
DRBD磁盘复制
DRBD是一种基于软件、基于网络的块复制存储解决方案,主要用于对服务器之间的磁盘、分区、逻辑卷等进行数据镜像,当用户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点)的数据就可以保证实时同步。常用架构如下:
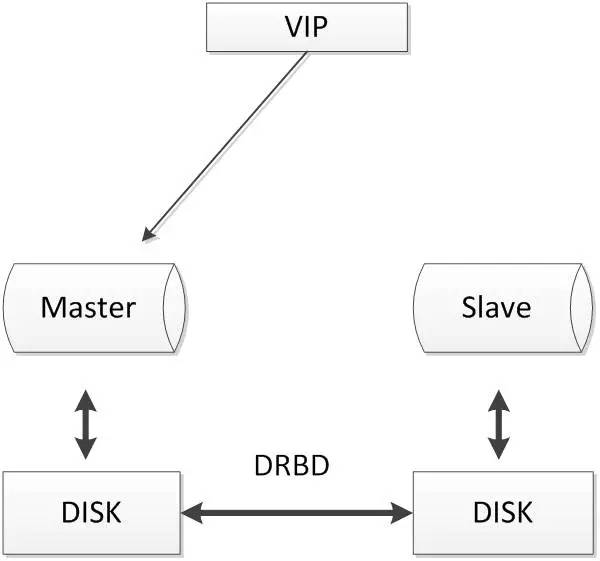
当本地主机出现问题,远程主机上还保留着一份相同的数据,可以继续使用,保证了数据的安全。
DRBD是linux内核模块实现的快级别的同步复制技术,可以与SAN达到相同的共享存储效果。
优点:
- 两节点即可,部署简单,切换逻辑简单;
- 相比于SAN储存网络,价格低廉;
- 保证数据的强一致性;
缺点:
- 对io性能影响较大;
- 从库不提供读操作;
分布式协议
MySQL cluster
MySQL cluster是官方集群的部署方案,通过使用NDB存储引擎实时备份冗余数据,实现数据库的高可用性和数据一致性。
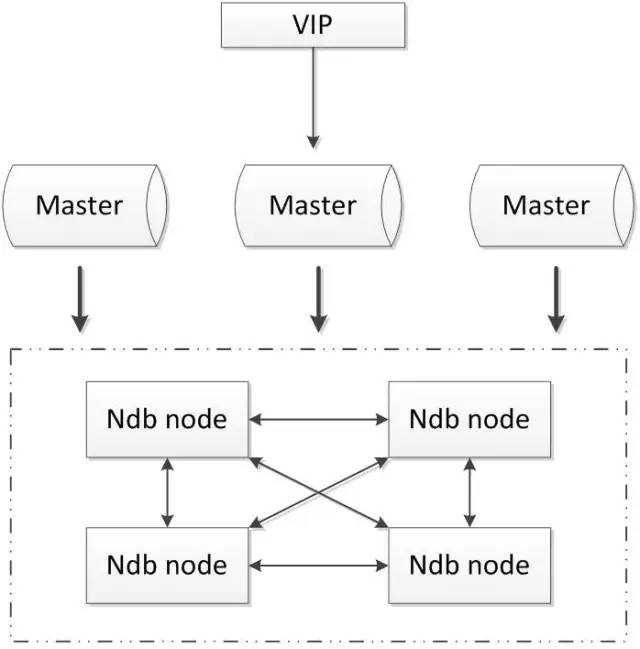
优点:
- 全部使用官方组件,不依赖于第三方软件;
- 可以实现数据的强一致性;
缺点:
- 国内使用的较少;
- 配置较复杂,需要使用NDB储存引擎,与MySQL常规引擎存在一定差异;
- 至少三节点;
Galera
基于Galera的MySQL高可用集群, 是多主数据同步的MySQL集群解决方案,使用简单,没有单点故障,可用性高。常见架构如下:
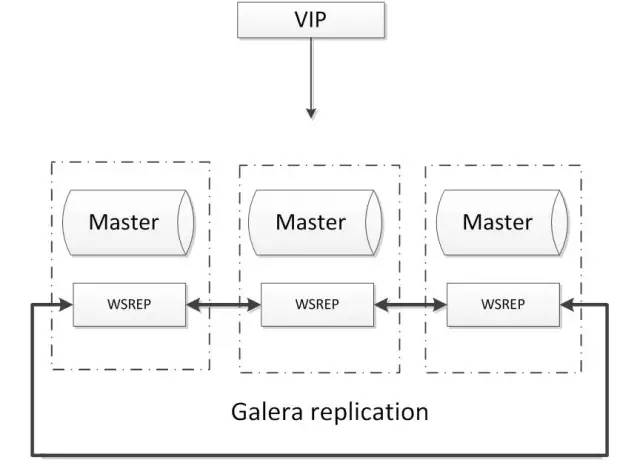
优点:
- 多主写入,无延迟复制,能保证数据强一致性;
- 有成熟的社区,有互联网公司在大规模的使用;
- 自动故障转移,自动添加、剔除节点;
缺点:
- 需要为原生MySQL节点打wsrep补丁
- 只支持innodb储存引擎
- 至少三节点
POAXS
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。这个算法被认为是同类算法中最有效的。Paxos与MySQL相结合可以实现在分布式的MySQL数据的强一致性。常见架构如下:
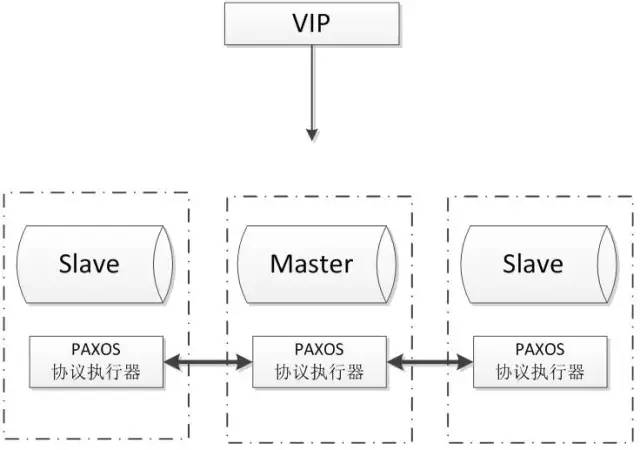
优点:
- 多主写入,无延迟复制,能保证数据强一致性;
- 有成熟理论基础;
- 自动故障转移,自动添加、剔除节点;
缺点:
- 只支持innodb储存引擎
- 至少三节点;
总结
看起来用mha保证主节点高可用,用raft保证半主从复制的数据一致,可能是一个比较好的办法。
关于mmm和mha的扩展阅读:https://zhangjunjia.github.io/2019/03/16/mysql-mmm-mha/